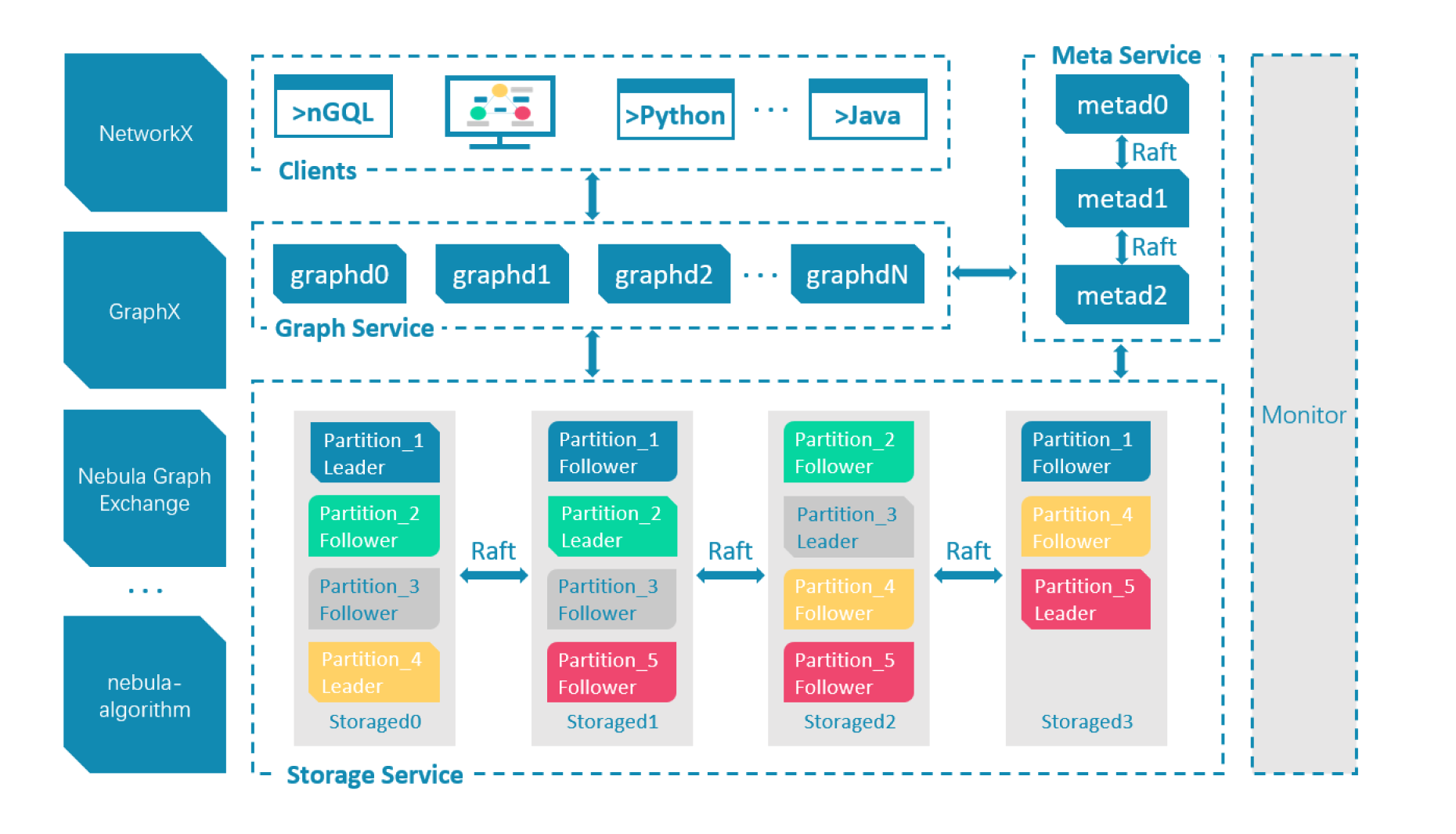
about








Why NebulaGraph?
What is Graph Database?
A graph is known as a diagram that illustrates a relationship between two things. Thus, a graph database can be assumed to be a database to understand relationships between data.
Graph databases are unlike traditional Relational Database Management System (RDBMS) most people are familiar. These databases house data in a table of columns and rows with little or no relation to each other.
Graph databases are fundamentally designed with a focus on the relationship between data sets. So, they require more intense and specialized processing capabilities. As a result, graph databases like NebulaGraph use sophisticated design and architecture.

Why Graph Database?
Graph databases are designed to uncover important relationships between many big data sets. In other words, it can connect the dots between multiple datasets that might otherwise just be sitting useless in silos. And graph databases are already widely used for such purposes.
Graph databases are used by data architects, data scientists, CIO, and others specifically because of their ability to deeply uncover relationships between datasets. Most graph databases can efficiently manage millions of transactions with little noticeable delay. For this reason, major organizations have used them for years now.
- Graph databases can help an organization understand how datasets relate
- They are ideal for real-time recommendations, transaction tracing, AI, etc.
- Data managers can truly maximize results from their big data analysis
Why NebulaGraph?
NebulaGraph is a highly performant linearly scalable graph database available for use via a shared-nothing distributed model. In several real production environments, data mining and technical performance has been proven to beat the performance of competing graph databases by multiple times over.
The goal behind NebulaGraph is to unleash the power of exponentially growing connected data unlike any other solution can.
- NebulaGraph securely process data sets of at least twice the size and twice as fast as any competing graph databases
- It is the only database that can store and process billions of data points with trillions of relational connections
- NebulaGraph is designed for scalability and recovery without disruption, ensuring the best business continuity available