
Performance
How to Select a Graph Database: Best Practices at RoyalFlush
This sharing is mainly from the perspective of (potential) users and discusses about what considerations the technical team will have when selecting a database. At the very beginning, our RoyalFlush Knowledge Graph team chose Neo4j when the knowledge graph strategy was started. However, during the using process, it turned out that Neo4j could not handle our growing business well. Therefore, the technical team came up with a solution: adding a multi-level cache between the database and the application layer. Although caching can alleviate the problem to a certain extent and improve the operation performance, it actually causes more problems.
So, we began to think about whether there is a graph database that can not only meet the current business needs, but also is capable of handling the future business growth. Thus, our Knowledge Graph team starts the journey of selecting an ideal graph database.
How to select a graph database

This speech can be divided into three parts: How to choose, What to choose, and Why. In addition, our RoyalFlush Knowledge Graph team and related businesses will be introduced at the end.
When selecting a Graph Database, we will consider the following aspects:
- Inclusive functions with outstanding performance
- Commercially mature products
- Active community
- Large amount of data to handle the current business and future business growth
- Open-source preferred
- Technical support
- Domestic preferred
Selecting a graph database is similar to select a stock. We will take information analysis, fundamental analysis, and technical analysis into consideration. In the world of the graph database, they mean:
- Information analysis: Whether the graph database meets the above seven demands
- Fundamental analysis: Whether the graph database is stable and durable
- Technical analysis: Whether the graph database meets the technical requirements
Information analysis

NOTE: The screenshot is the DB-Engine ranking in Sep. 2021 when this talk was given.
Generally, we will go to DB-Engine for the information about the graph database. You can see that Neo4j ranks first here. After all, it is the earliest graph database that is relatively mature. After a round of research, we found that Neo4j did a great job in marketing. If you search "graph database" on Baidu or Google, their ads will show up.
In this DB-Engine ranking, you can see other famous graph databases like JanusGraph (ranked seventh). So, among so many databases, how do we determine the database we will ultimately use?

As for the ranking rules of DB-Engine, it is based on the search results of Google and Bing, keyword trends in Google Trends, discussions on Stack Overflow, DBA Stack Exchange, the number of posts on recruitment websites like Indeed and Linkedin, and the amount of discussions on social networks like Twitter.
We can find a problem: the above websites are either inaccessible in China or relatively niche websites.
Therefore, the ranking on DB-Engine is actually biased for some domestic products. At least its data certainly cannot reflect the true conditions. If some domestic products are also included, the rankings of HugeGraph and NebulaGraph in this DB-Engine ranking will definitely ascend a lot.
After knowing what is DB-Engine, let's filter the information on this DB-Engine ranking:


From the view of the information analysis, these databases do not meet the needs of our RoyalFlush Knowledge Graph team. This result also proves that the DB-Engine ranking results are not so accurate. For example, some databases ranked before NebulaGraph are already inactive or no longer updated products. The above screenshots are all from DB-Engine.
Fundamental analysis


After the information analysis, we filter out 6 graph database products including Neo4j, Orient DB, Dgraph, JanusGraph, HugeGraph, Nebula, etc. These 6 products are relatively active and support multiple languages.
According to the earliest release time of the product, Neo4j is ranked first, which was released in 2007, followed by OrientDB, Dgraph, JanusGraph, HugeGraph, and NebulaGraph which released in 2019. The higher the ranking of the database product, the higher its language support level, and the more complete its system functions. This is also where the new databases need to be perfected and improved.
The functions of many products like HugeGraph and Neo4j are only supported in the Enterprise Edition. We also need to know the content of their Enterprise Edition and the corresponding pricing.

The above picture is more interesting. It points out the order of magnitude supported by various graph databases in different scenarios. For example, Neo4j supports billions of nodes, trillions of relationships with millisecond response time and unlimited elasticity. OrientDB is more interesting. It supports unlimited data. I don't know how it achieves this value. Dgraph did not clarify the amount of data, but said that it provides Google production level scale and throughput, with low enough latency to be serving real-time user queries, over terabytes of structured data.
As for the rest two, one is HugeGraph, open sourced by Baidu, and the other is NebulaGraph. Nebula is still relatively dominant. It is capable of hosting graphs with hundreds of billions of vertices and trillions of edges, and serving queries with millisecond-latency.
Technical analysis

After the information analysis and fundamental analysis, there is actually no clear winner. Let's look at the technical analysis. Since HugeGraph and JanusGraph have similar architectures and the technical support of OrientDB is plain, we will only focus on the following three graph databases: Neo4j, HugeGraph, and NebulaGraph.
Neo4j only supports isomorphic deployment and does not support heterogeneous deployment, so it cannot take advantage of each machine. For example, some machines may be computational-oriented, and some machines have strong IO. If you follow Neo4j's deployment settings, it requires that each machine is in the same condition. The analysis and performance improvement of Neo4j mainly relies on the virtual machine composed of two fabrics to provide regional partitioning capabilities (the green part of the above figure).
At the architecture level, the separated architecture of storage and computing of NebulaGraph and HugeGraph has more advantages. At least users can configure the machines according to the realities of the business department.

HugeGraph supports a variety of storage engines in the storage area, which can be connected to a variety of third-party engines, and then a computing framework is added on this basis. Above the computing framework is the interface layer, such as Huge Console, Huge Loader, etc.
In computing, the storage engine at the bottom mainly provides OLTP and OLAP. Here the storage engine of HugeGraph is not self-provided, but mainly depends on other storage engines. It may not be as good as Nebula's own storage engine. For example, the third-party storage engine we use is HBase. The real-time performance of HBase is very unsatisfactory. At this time, using it as a storage engine will affect the performance of the upper layer.

NebulaGraph also applies an architecture that separates storage and computing. Each layer can be expanded infinitely. You can expand the storage/computing layer if it is full. Relatively speaking, this architecture is relatively advanced.
After talking about the architecture, RoyalFlush also refers to the test results of other technical teams:
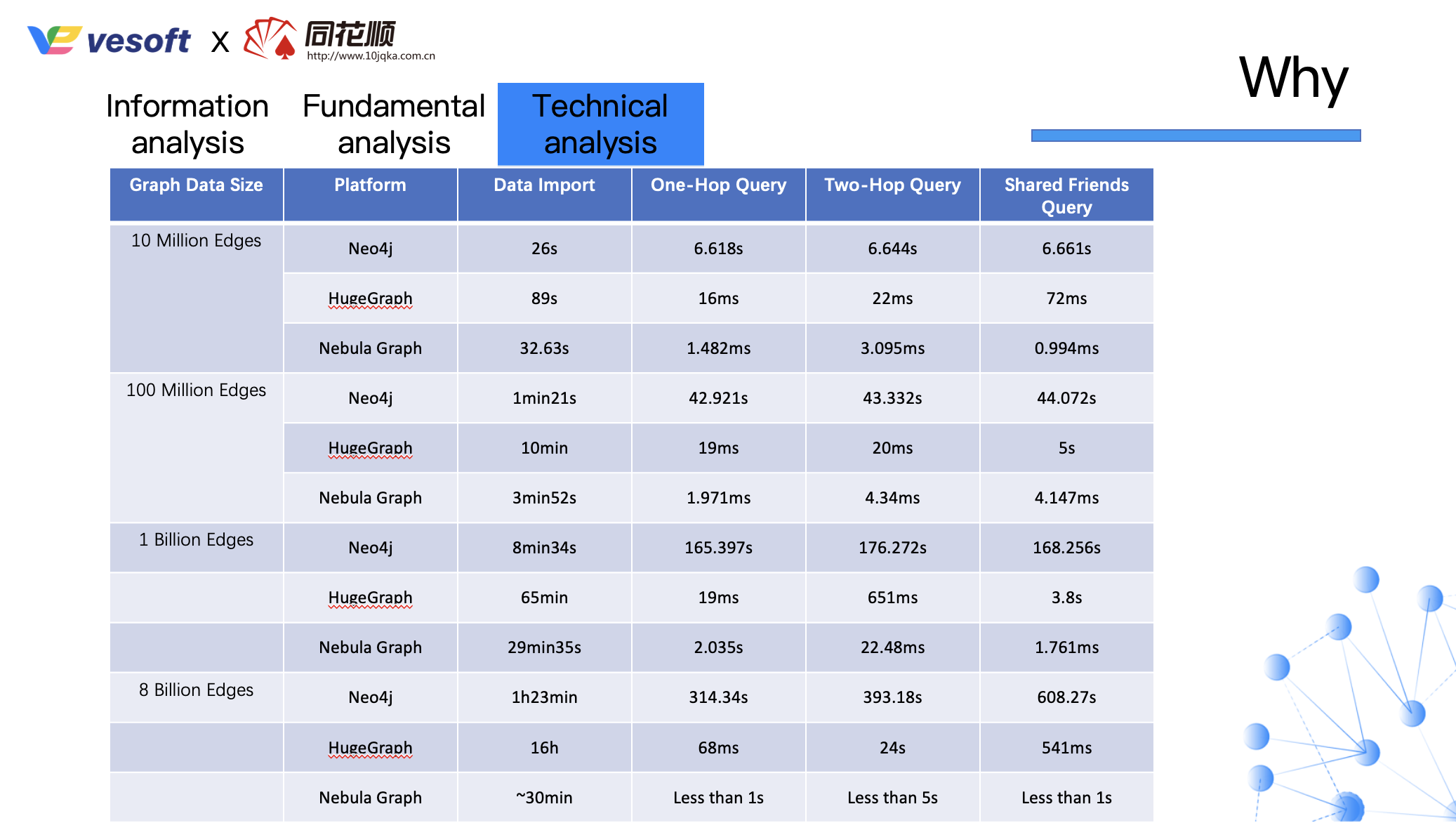
This is the performance test of v1.x carried out by the Tencent Cloud Security Team.

This is the performance comparison of Nebula, Dgraph, and HugeGraph carried out by the Meituan NLP team. Here, HugeGraph uses HBase as the storage engine, while Dgraph and NebulaGraph uses RocksDB. As mentioned before, HBase is at a disadvantage in real-time performance. If all three databases use the KV storage engine, there will be no such a large gap in the results.

The following is the performance test carried out by RoyalFlush. We not only compare different graph databases, but also compare two query languages (native nGQL and nGQL that is compatible with openCypher) of NebulaGraph.
From the data, we can see that the native query language nGQL has better performance (nebula-ngql and nebula-cypher in the figure above). In the multi-hop query, you can see that for queries that are more than 5 hops, Neo4j stays in a timeout state.
In terms of performance, Nebula still has a relatively large advantage over Neo4j.

Considering factors such as architecture, performance, community support, etc., we will still choose a graph database that is more suitable for us, namely NebulaGraph. Although some minor problems were found in the using process:
- Chinese identifiers are not supported.
- Syntax error prompts are not user-friendly.
- Parameterized queries are not supported in Java.
- The source vertex ID must be specified in GO queries.
In general, NebulaGraph still meets our business requirements.
RoyalFlush · the Knowledge Graph team

Finally, let me introduce our RoyalFlush Knowledge Graph Team. Our main serving businesses are intelligent dialogue system, system recommendation, search engines, investment strategies, and some businesses such as multi-mode integration, stock tips, investment consulting and education, which may expand later.

At present, we maintain several graphs. One is the graph of the industry chain, which means that the data are public. The graph of the industry chain is constructed through semantic extraction.
NOTE: The right part in the above figure is an example of Graph used in the industry chain, which shows leading enterprises rankings, qualified enterprises rankings, and non-listed benchmarking enterprises rankings.

We also maintain the graph of the supply chain,
NOTE: The right part in the above figure is an example of graph used in the supply chain, which displays acquired clients and co-supplier of an enterprise.

the graph of personal relationships,
NOTE: The right part in the above figure is a true case of graph used in personal relationships.

and the graph of enterprises, so as to meet the financial investment needs of RoyalFlush. The above is all that I'd like to share today. Thank you!
NOTE: The right part in the above figure is an example of graph used in enterprises, which shows infinite upward and downward penetration of equity relations, he beneficiary and actual controller of an enterprise etc.
Welcome to join our Slack channel if you want to discuss with the rest of the NebulaGraph community!



