
Features
Nebula Flink Connector: Implementation and Practices

In the scenarios of relational network analysis, relationship modeling, and real-time recommendation, using graph databases for background data is becoming popular, and some scenarios, such as recommendation systems and search engines, require high real-time graph data. To improve the real-time performance of data, stream processing is widely used for incremental processing of updated data in real-time. To support the stream processing of graph data, the NebulaGraph team developed Nebula Flink Connecter to empower Flink to operate stream processing of data in NebulaGraph.
Flink is a new generation of computing engines that can support both stream and batch processing of data. It reads data from a third-party storage engine, processes them, and then writes them to another storage engine. A Flink Connector works like a connector, connecting the Flink computing engine to an external storage system.
Flink can use four methods to exchange data with an external source:
- The pre-defined API of Source and Sink
- The bundled connectors, such as JDBC connector.
- The Apache Bahir connectors. Apache Bahir was part of Apache Spark. It was intended to provide the implementation of extensions and/or plug-ins, connectors, and other pluggable components that are not limited to Spark.
- Asynchronous I/O. In stream processing, it is often necessary to interact with external storage systems, such as associating a table in MySQL. If synchronous I/O is used, a lot of time is consumed for waiting, which has an influence on throughput and latency. But in asynchronous I/O mode, multiple requests can be handled concurrently, so the throughput is improved and the latency is reduced.
This post introduces Nebula Flink Connector. Like the pre-defined Flink connectors, it enables Flink to read data from and write data to NebulaGraph.
Connector Source
As a stream-processing framework, Flink can handle both bounded and unbounded data. The unbounded data are the continuous flow of data that cannot be terminated, and it is the data that is processed by real-time stream processing. The data processed by batch processing is bounded data. As for Flink, the system that provides data to be processed by Flink is called Source.
For Nebula Flink Connector, NebulaGraph is the Source. Flink provides rich Connector components, allowing users to define external storage systems as its Sources.
About Source
The Source enables Flink to get access to external data sources. The source capability of Flink is mainly implemented with read related APIs and the addSource method. When using the addSource method to read data from an external system, you can use a Flink Bundled Connector or customize a Source.
How to use Flink Source is shown in this figure.

In this section, we focus on how to customize NebulaGraph Source.
1.2 Customize Source
In Flink, either StreamExecutionEnvironment.addSource(sourceFunction) or ExecutionEnvironment.createInput(inputFormat) can be used to add a data source to your program.
Flink provides a number of built-in SourceFunction. Developers can customize a non-parallel Source by inheriting from RichSourceFunction or a parallel Source by inheriting from RichParallelSourceFunction. RichSourceFunction and RichParallelSourceFunction have the features of both SourceFunction and RichFunction. Of them, SourceFunction is responsible for data generation, and RichFunction is responsible for resource management. Of course, you can implement only SourceFunction to define the simplest DataSource that has the function of getting data only.
Generally, a complete Source is customized by implementing the RichSourceFunction class, which has the capabilities of both RichFunction and SourceFunction. Therefore, to enable NebulaGraph to be a Source of Flink, we must implement the methods provided in RichSourceFunction.
1.3 Implementation of NebulaGraph Source
Two options are provided for you to use the custom NebulaGraph Source implemented in Nebula Flink Connector, namely addSource and createInput.
Here is the class diagram of NebulaGraph Source implementation.

addSource
This method is implemented through the NebulaSourceFunction class, which inherits from RichSourceFunction and realizes these methods:
- open Prepares information for connecting to NebulaGraph and obtains the connection to the Meta Service and the Storage Service.
- close Releases resources after data reading is done. Closes the connection to NebulaGraph.
- run
Starts data reading and fills the data into
sourceContext. - cancel Called to release the resources when the Flink job is canceled.
createInput
This method is implemented through the NebulaInputFormat class, which inherits from RichInputFormat and realizes these methods:
- openInputFormat
Prepares
inputFormatand obtains the connection. - closeInputFormat Releases resources after data reading is done, and closes the connection to NebulaGraph.
- getStatistics Obtains the basic statistics of the source data.
- createInputSplits
Creates
genericInputSplitbased on the configured partition number. - getInputSplitAssigner Returns the input split assigners and returns all splits of the source in the order of the original computing.
- open
Starts reading data of
inputFormat, converts the format of the data into Flink format, and constructs iterators. - close Prints the reading logs after data reading is done.
- reachedEnd Determines whether the reading is done or not.
- nextRecord Reads the next record through the iterator.
The data read from Source with addSource is DataStreamSource of Flink, which indicates the starting point of the data flow.
The data read with createInput is DataSource of Flink, which is an operator to create new datasets. This operator can be used for further conversion. DataSource can be used for other operations with withParameters.
Use Custom NebulaGraph Source
To enable Flink to read data from NebulaGraph, NebulaSourceFunction and NebulaOutputFormat must be constructed, and NebulaGraph must be registered as the data source with the addSource or createInput method.
To construct NebulaSourceFunction and NebulaOutputFormat, you must configure the client parameters and execution parameters as follows:
NebulaClientOptions
- Specifies the IP address of the Meta Service of NebulaGraph is necessary for NebulaSource.
- username
- password
VertexExecutionOptions
- Specifies the name of a NebulaGraph space to be read.
- Specifies a tag to be read.
- Specifies properties of the tag.
- Determine reading all the properties or not. The default value is
false. If this parameter is set totrue, the Fields configuration is not effective. - Specifies the maximum size of each batch to be read. The default value is
2000.
EdgeExecutionOptions
- Specifies the name of a NebulaGraph space to be read.
- Specifies an edge type to be read.
- Specifies properties of the edge type.
- Determine whether reading all the properties or not. The default value is
false. If this parameter is set totrue, the property configuration is not effective. - Specifies the maximum size of each batch to be read. The default value is
2000.
// Contructs the necessary parameters for the NebulaGraph client
NebulaClientOptions nebulaClientOptions = new NebulaClientOptions
.NebulaClientOptionsBuilder()
.setAddress("127.0.0.1:45500")
.build();
// Creates connectionProvider
NebulaConnectionProvider metaConnectionProvider = new NebulaMetaConnectionProvider(nebulaClientOptions);
// Constructs the necessary parameters for reading data from NebulaGraph
List<String> cols = Arrays.asList("name", "age");
VertexExecutionOptions sourceExecutionOptions = new VertexExecutionOptions.ExecutionOptionBuilder()
.setGraphSpace("flinkSource")
.setTag(tag)
.setFields(cols)
.setLimit(100)
.builder();
// Constructs NebulaInputFormat
NebulaInputFormat inputFormat = new NebulaInputFormat(metaConnectionProvider)
.setExecutionOptions(sourceExecutionOptions);
// Method 1: Uses createInput to enable Flink to read data from NebulaGraph
DataSource<Row> dataSource1 = ExecutionEnvironment.getExecutionEnvironment()
.createInput(inputFormat);
// Method 2: Uses addSource to enable Flink to read data from NebulaGraph
NebulaSourceFunction sourceFunction = new NebulaSourceFunction(metaConnectionProvider)
.setExecutionOptions(sourceExecutionOptions);
DataStreamSource<Row> dataSource2 = StreamExecutionEnvironment.getExecutionEnvironment()
.addSource(sourceFunction);
You can edit the Nebula Source Demo, package it, and submit it to a Flink cluster for execution.
The demo program reads the vertex data from NebulaGraph and prints them. In this Flink job, NebulaGraph is the Source, and print is the Sink. The execution result is as follows.

The Source sent 59,671,064 records and the Sink received 59,671,064 records.
Connector Sink
For Nebula Flink Connector, the Sink is NebulaGraph. Flink provides users with rich Connector components to customize data pools to receive data flow processed by Flink.
About Sink
A Sink is the output of the data processed by Flink. It is mainly responsible for the output and persistence of real-time data processing. For example, Sinks support writing data to stdout, to files, to sockets, and to external systems.
A Sink of Flink works by calling write related APIs or the DataStream.addSink method to implement writing data flow to an external store.
Like the Source of a Flink Connector, a Sink also allows users to customize external storage systems to be a data pool of Flink.
How to use Flink Sink is shown in this figure.

This section focuses on how to enable NebulaGraph to be a Sink of Flink.
Customize Sink
In Flink, you can use DataStream.addSink or DataStream.writeUsingOutputFormat to write Flink data flow into a user-defined data pool.
To customize a Sink, you can use the built-in Sink Functions, or implement SinkFunction and inherit from RichOutputFormat.
Implementation of NebulaGraph Sink
In Nebula Flink Connector, NebulaSinkFunction is implemented. Developers can call DataSource.addSink and pass it in the NebulaSinkFunction object as a parameter to write the Flink data flow to NebulaGraph.
Nebula Flink Connector is developed based on Flink 1.11-SNAPSHOT. In this version, writeUsingOutputFormat is deprecated (Here is its source code for your reference). If you want to use NebulaGraph Sink, you must use DataStream.addSink.
/** @deprecated */
@Deprecated
@PublicEvolving
public DataStreamSink<T> writeUsingOutputFormat(OutputFormat<T> format) {
return this.addSink(new OutputFormatSinkFunction(format));
}
The class diagram of NebulaGraph Sink is as follows.
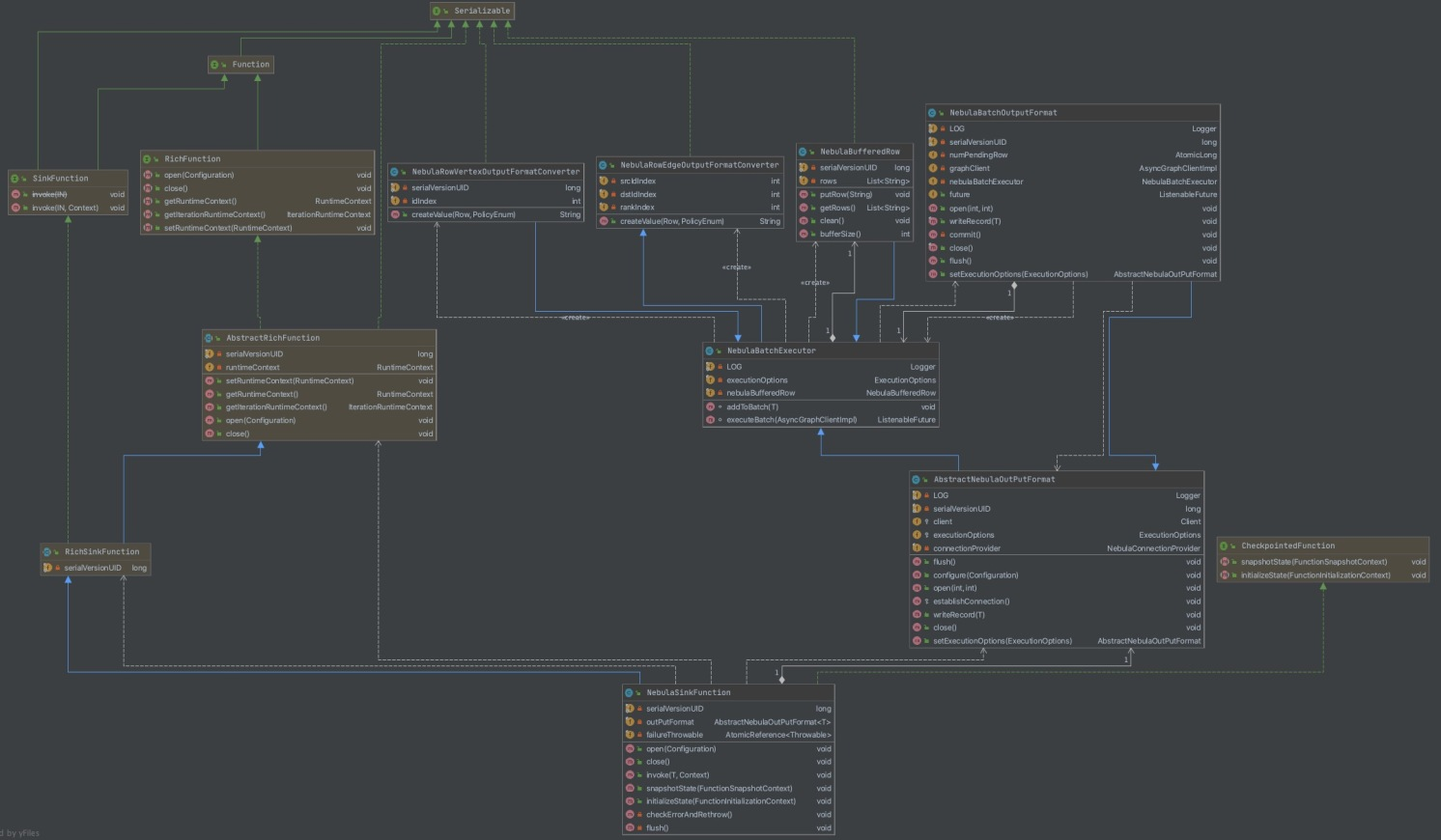
In the class diagram, NebulaSinkFunction and NebulaBatchOutputFormat are the most important classes.
NebulaSinkFunction inherits from AbstractRichFunction and these methods are implemented:
- open
Prepares resources by calling the
openmethod ofNebulaBatchOutputFormat. - close
Releases resources by calling the
closemethod ofNebulaBatchOutputFormat. - invoke
Writes data by calling the
writemethod ofNebulaBatchOutputFormat. This is the core method of Sink. - flush
Submits data by calling the
flushmethod ofNebulaBatchOutputFormat.
NebulaBatchOutputFormat inherits from AbstractNebulaOutPutFormat, and the latter inherits from RichOutputFormat. These methods are implemented:
- open
Prepares the connection to the Graph Service of NebulaGraph and initializes
nebulaBatchExecutor. - close Submits the last batch of data, waits for the callback result, and closes the connection to NebulaGraph.
- writeRecord
A core method. Writes data into
nebulaBufferedRowand submits a job to write data when the data size reaches the configured limit. The writing process of NebulaGraph Sink is asynchronous, so a callback to obtain the execution result is necessary. - flush
Writes data to NebulaGraph when data exists in
nebulaBufferedRow.
In AbstractNebulaOutputFormat, NebulaBatchExecutor is called for batch management and batch submission of data, and the result of a batch submission is received by defining a callback function. The code is as follows.
/**
* write one record to buffer
*/
@Override
public final synchronized void writeRecord(T row) throws IOException {
nebulaBatchExecutor.addToBatch(row);
if (numPendingRow.incrementAndGet() >= executionOptions.getBatch()) {
commit();
}
}
/**
* put record into buffer
*
* @param record represent vertex or edge
*/
void addToBatch(T record) {
boolean isVertex = executionOptions.getDataType().isVertex();
NebulaOutputFormatConverter converter;
if (isVertex) {
converter = new NebulaRowVertexOutputFormatConverter((VertexExecutionOptions) executionOptions);
} else {
converter = new NebulaRowEdgeOutputFormatConverter((EdgeExecutionOptions) executionOptions);
}
String value = converter.createValue(record, executionOptions.getPolicy());
if (value == null) {
return;
}
nebulaBufferedRow.putRow(value);
}
/**
* commit batch insert statements
*/
private synchronized void commit() throws IOException {
graphClient.switchSpace(executionOptions.getGraphSpace());
future = nebulaBatchExecutor.executeBatch(graphClient);
// clear waiting rows
numPendingRow.compareAndSet(executionOptions.getBatch(),0);
}
/**
* execute the insert statement
*
* @param client Asynchronous graph client
*/
ListenableFuture executeBatch(AsyncGraphClientImpl client) {
String propNames = String.join(NebulaConstant.COMMA, executionOptions.getFields());
String values = String.join(NebulaConstant.COMMA, nebulaBufferedRow.getRows());
// construct insert statement
String exec = String.format(NebulaConstant.BATCH_INSERT_TEMPLATE, executionOptions.getDataType(), executionOptions.getLabel(), propNames, values);
// execute insert statement
ListenableFuture<Optional<Integer>> execResult = client.execute(exec);
// define callback function
Futures.addCallback(execResult, new FutureCallback<Optional<Integer>>() {
@Override
public void onSuccess(Optional<Integer> integerOptional) {
if (integerOptional.isPresent()) {
if (integerOptional.get() == ErrorCode.SUCCEEDED) {
LOG.info("batch insert Succeed");
} else {
LOG.error(String.format("batch insert Error: %d",
integerOptional.get()));
}
} else {
LOG.error("batch insert Error");
}
}
@Override
public void onFailure(Throwable throwable) {
LOG.error("batch insert Error");
}
});
nebulaBufferedRow.clean();
return execResult;
}
NebulaGraph Sink writes data in batches and asynchronously, so NebulaGraph client must not be closed before the write job is submitted. To prevent this, it is necessary to submit data in the cache in batches and wait for the write operation to complete before the resources are released at the end of the business. The code is as follows.
/**
* commit the batch write operator before release connection
*/
@Override
public final synchronized void close() throws IOException {
if(numPendingRow.get() > 0){
commit();
}
while(!future.isDone()){
try {
Thread.sleep(10);
} catch (InterruptedException e) {
LOG.error("sleep interrupted, ", e);
}
}
super.close();
}
2.4 Use Custom NebulaGraph Sink
When Flink uses the Sink to write data to NebulaGraph, it is necessary to map the Flink data flow to the data format that NebulaGraph Sink can recognize. To use the custom NebulaGraph Sink, you must pass the NebulaSinkFunction as a parameter to the addSink method to write the Flink data flow.
- NebulaClientOptions
- Address: Specifies the IP addresses of the Graph Service of NebulaGraph.
- username
- password
- VertexExecutionOptions
- Specifies the name of a NebulaGraph space to write data in.
- Specifies a tag to be written.
- Specifies properties of the tag.
- Specifies the index on the Flink data row where the vertex to be written is.
- Specifies the vertex data size limit to be written at a time. The default value is 2000.
- EdgeExecutionOptions
- Specifies the name of a NebulaGraph space to write data in.
- Specifies an edge type to be written.
- Specifies properties of the edge type.
- Specifies the index on the Flink data row where the source vertices to be written are.
- Specifies the index on the Flink data row where the destination vertices to be written are.
- Specifies the index on the Flink data row where the ranking information of the edges is.
- Specifies the edge data size limit to be written at a time. The default value is 2000.
/// The necessary parameters for connecting to the NebulaGraph client
NebulaClientOptions nebulaClientOptions = new NebulaClientOptions
.NebulaClientOptionsBuilder()
.setAddress("127.0.0.1:3699")
.build();
NebulaConnectionProvider graphConnectionProvider = new NebulaGraphConnectionProvider(nebulaClientOptions);
// The necessary parameters for writing data to NebulaGraph
List<String> cols = Arrays.asList("name", "age")
ExecutionOptions sinkExecutionOptions = new VertexExecutionOptions.ExecutionOptionBuilder()
.setGraphSpace("flinkSink")
.setTag(tag)
.setFields(cols)
.setIdIndex(0)
.setBatch(20)
.builder();
// Writes data to NebulaGraph
dataSource.addSink(nebulaSinkFunction);
You can use the demo program of NebulaGraph Sink to transfer data between two graph spaces of NebulaGraph. The flinkSource graph space is the Source. After Flink reads its data and operates map conversion, all the data is written to another graph space, flinkSink, the Sink.
Catalog
Before Flink 1.11.0, to use Flink to read data from or write data to an external system, you must manually read the schema of the source. For example, if you want to read data from or write data to NebulaGraph, you must know the schema before the read or write operation. If the schema in NebulaGraph is updated, you must manually update the Flink job to make sure that types are matching. Any mismatch may cause failures in the job. Such operation is redundant and tedious.
Since from Flink 1.11.0, Flink Connectors can automatically obtain the schema of the data source or match the data without knowing the schema of an external storage system.
For now, Nebula Flink Connector can be used to read data from and write data to NebulaGraph. But if we want to implement schema matching, Catalog management is necessary. To make sure that data in NebulaGraph is safe, Nebula Flink Connector only supports reading Catalog, but not editing or writing Catalog.
When Nebula Flink Connector gets access to data of some specified types, the complete path is as follows: <graphSpace>.<VERTEX.tag> or <graphSpace>.<EDGE.edge>.
It can be used as follows:
String catalogName = "testCatalog";
String defaultSpace = "flinkSink";
String username = "root";
String password = "nebula";
String address = "127.0.0.1:45500";
String table = "VERTEX.player"
// define Nebula catalog
Catalog catalog = NebulaCatalogUtils.createNebulaCatalog(catalogName,defaultSpace, address, username, password);
// define Flink table environment
StreamExecutionEnvironment bsEnv = StreamExecutionEnvironment.getExecutionEnvironment();
tEnv = StreamTableEnvironment.create(bsEnv);
// register customed nebula catalog
tEnv.registerCatalog(catalogName, catalog);
// use customed nebula catalog
tEnv.useCatalog(catalogName);
// show graph spaces of NebulaGraph
String[] spaces = tEnv.listDatabases();
// show tags and edges of NebulaGraph
tEnv.useDatabase(defaultSpace);
String[] tables = tEnv.listTables();
// check tag player exist in defaultSpace
ObjectPath path = new ObjectPath(defaultSpace, table);
assert catalog.tableExists(path) == true
// get nebula tag schema
CatalogBaseTable table = catalog.getTable(new ObjectPath(defaultSpace, table));
table.getSchema();
For more Catalog interfaces supported by Nebula Flink Connector, see NebulaCatalog.java.
Exactly-once
For a Flink Connector, Exactly-once means that, because of the checkpoint algorithm, Flink ensures that each incoming event affects the final result only once. Any fault in the data processing will not cause data duplication or loss.
To provide end-to-end Exactly-once semantics, an external storage system of Flink must provide a means to commit or roll back writes that coordinate with the checkpoins of Flink. Flink provides an abstraction to implement the end-to-end Exactly-once, namely TwoPhaseCommitSinkFunction, to implement a two-phase commit.
To implement Exactly-once semantics for data output, these four functions must be implemented:
- beginTransaction Creates a temporary file under the temporary directory on the destination file system before the transaction begins. Then writes data in this file during processing the data.
- preCommit Closes the file and stops writing in the pre-commit phase. Starts a new transaction to write any subsequent data for the next checkpoint.
- commit Moves the files processed in the pre-commit phase atomically to the actual destination directory in the commit phase. The two-phase process increases the visibility latency of the output data.
- abort Deletes temporary files in the termination phase.
From the preceding methods, the two-phase commit mechanism of Flink requires that the Source support data retransmission, and the Sink supports transaction commit and idempotent write.
NebulaGraph v1.1.0 does not support transactions, but it supports idempotent write, which means one record can be written multiple times and the record is consistent. Therefore, the At-least-Once mechanism of Nebula Flink Connector can be implemented through the checkpoint algorithm, and the Exactly-Once of Sink can be indirectly implemented with the idempotency of multiple writes.
To use the fault tolerance feature of NebulaGraph Sink, make sure that the checkpoint is enabled in the Flink execution environment.
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.enableCheckpointing(10000) // checkpoint every 10000 msecs
.getCheckpointConfig()
.setCheckpointingMode(CheckpointingMode.AT_LEAST_ONCE);
Reference
- Nebula Source Demo [testNebulaSource]:https://github.com/vesoft-inc/nebula-java/blob/v1.0/examples/src/main/java/org/apache/flink/FlinkDemo.java
- Nebula Sink Demo [testSourceSink]:https://github.com/vesoft-inc/nebula-java/blob/v1.0/examples/src/main/java/org/apache/flink/FlinkDemo.java
- Apache Flink:https://github.com/apache/flink
- Flink Documentation:https://flink.apache.org/flink-architecture.html and https://ci.apache.org/projects/flink/flink-docs-release-1.12/
- flink-connector-jdbc:https://github.com/apache/flink/tree/master/flink-connectors/flink-connector-jdbc



