
DeploymentTools
Nebula Operator Overview: Automated Operation on Kubernetes

Before introducing Nebula Operator, you should know what the Operator is.
An Operator aims to package, deploy, and manage Kubernetes applications. By extending the functionality of the Kubernetes API, it creates, configures, and manages complex application instances on behalf of a user. It is built based on the Custom Resource Definition (CRD) and its associated Controller, covering domain or application-specific knowledge to automate the entire life cycle of the software it manages.
In Kubernetes, controllers of the control plane implement control loops that repeatedly compare the desired state of a cluster with its actual state. If the actual state does not match the desired state, the controller continues managing internal business logic until the desired state is achieved.

Nebula Operator abstracts deployment management of NebulaGraph as CRD. By combining multiple built-in API objects including StatefulSet, Service, and ConfigMap, the routine management and maintenance of NebulaGraph are coded as a control loop. When a CR instance is submitted, Nebula Operator drives the database cluster to the final state according to the control process.
Functionalities of Nebula Operator
Custom Resource Definition
Here is the CRD file for the deployment of a NebulaGraph cluster. From it, you can see the core functionalities of Nebula Operator.
apiVersion: apps.nebula-graph.io/v1alpha1
kind: NebulaCluster
metadata:
name: nebula
namespace: default
spec:
graphd:
resources:
requests:
cpu: "500m"
memory: "500Mi"
replicas: 1
image: vesoft/nebula-graphd
version: v2.0.0
storageClaim:
resources:
requests:
storage: 2Gi
storageClassName: gp2
metad:
resources:
requests:
cpu: "500m"
memory: "500Mi"
replicas: 1
image: vesoft/nebula-metad
version: v2.0.0
storageClaim:
resources:
requests:
storage: 2Gi
storageClassName: gp2
storaged:
resources:
requests:
cpu: "500m"
memory: "500Mi"
replicas: 3
image: vesoft/nebula-storaged
version: v2.0.0
storageClaim:
resources:
requests:
storage: 2Gi
storageClassName: gp2
reference:
name: statefulsets.apps
version: v1
schedulerName: default-scheduler
imagePullPolicy: IfNotPresent
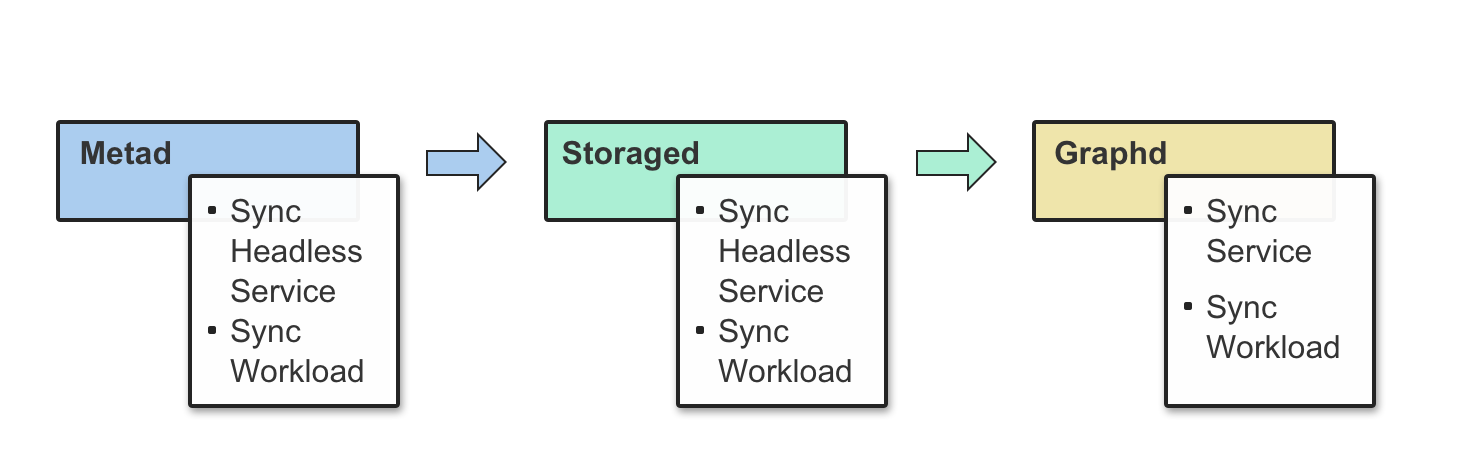
In the spec section, three items must be focused, that is, graphd, metad, and storaged. They represent Graph Service, Meta Service, and Storage Service respectively. The controllers will check the state of StatefulSet, Service, and ConfigMap in sequence in the control loop. If a dependent API object is not created or NebulaGraph component service regulation is abnormal, the control loop will be terminated and wait for the next one. This process is repeated again and again.
At present, only the essential configuration parameters for the operation are provided as CRDs, including resources, replicas, image, and schedulerName. In the future, more configuration parameters will be provided for Nebula Operator to meet your scenarios.
Scaling
Scaling out Storage is divided into two stages. In the first stage, you need to wait for the status of all newly created Pods to be Ready. In the second stage, the BALANCE DATA command is executed. The execution of BALANCE DATA is defined in the StorageBalancer CRD. Through both stages, the scaling process of the controller replicas is decoupled from the balancing data process to realize the customization of the balancing data task such as adding task execution time and executing it at low traffic. Such an implementation can effectively reduce the impact of data migration on online services, which is in line with NebulaGraph principle: Balancing data is not fully automated and when to balance data is decided by users.
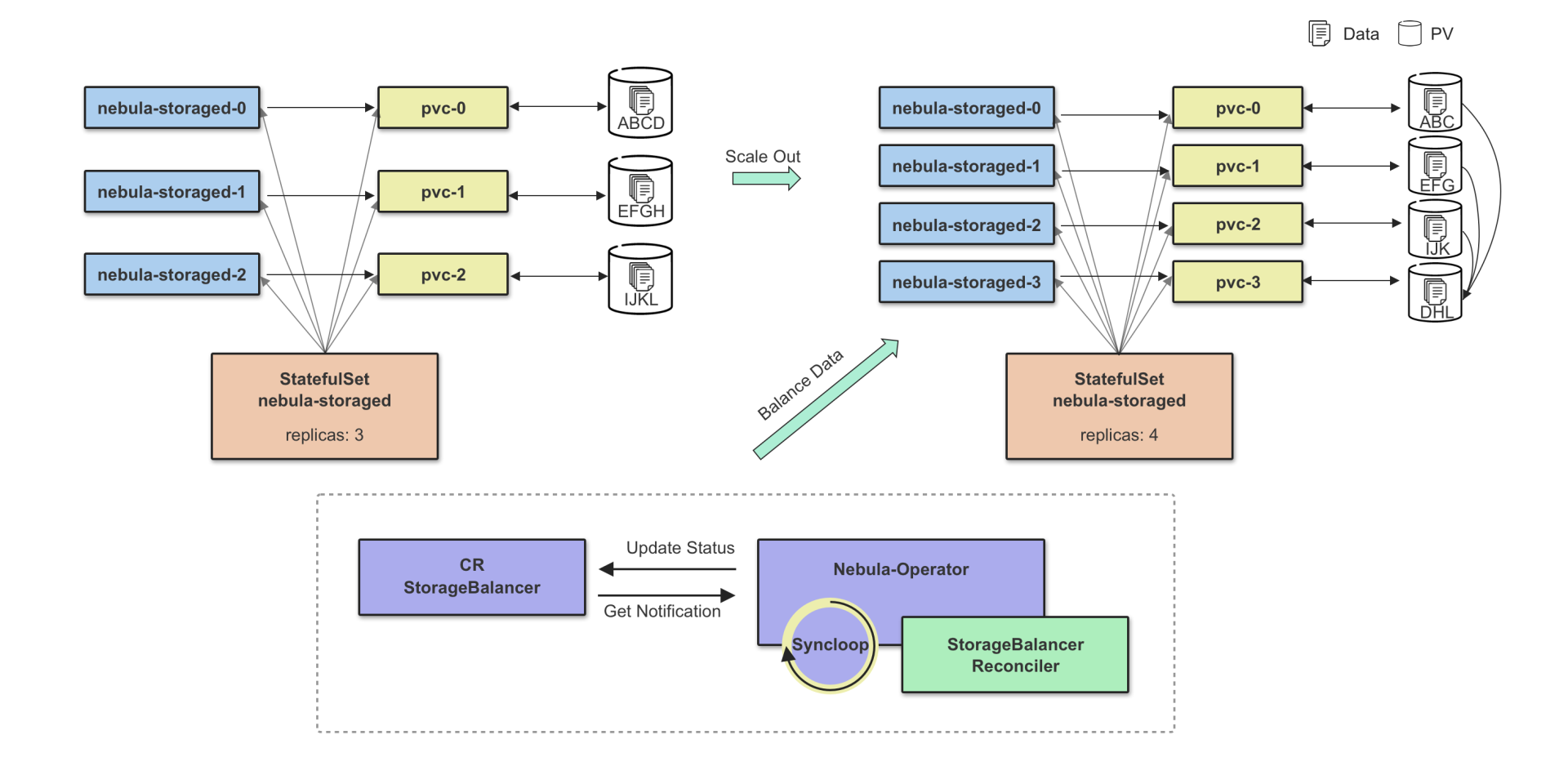
Scaling in and out Storage are the opposite processes. To scale in Storage, some nodes must be removed safely, which can be completed by running the BALANCE DATA REMOVE $host_list command internally. After the nodes are removed, the size of Storage Pods will be shrunk.
NOTE: The following figures show how Storage is scaled in, but it cannot be used as a deployment reference. In a high-availability scenario, three online replicas are necessary.


Balance Scheduling
For scheduling, Nebula Operator provides two options: the default scheduler and the custom scheduler based on the scheduler extender interface.
Topology spread constraints of the default scheduler can be used to spread Pods evenly across your cluster. By default, the key of node label is set to kubernetes.io/hostname in Nebula Operator. It will be configurable in the future. The affinity-based scheduling policies are not applied because such policies control how Pods are packed or scattered. "PodAffinity" is to pack multiple Pods into a specific topology domain, which is called "packed", while "PodAntiAffinity" is to ensure that only one Pod can be scheduled into a single topology domain, which is called "scattered". However, these scheduling policies cannot meet the scenarios that require Pods to be spread as evenly as possible, especially in a distributed scenario, where high-availability needs to be spread across multiple topology domains.
Of course, if you are using an earlier version of Kubernetes and cannot experience the topology spread constraints feature, you can use Nebula-Scheduler. Its core logic is to ensure that the Pods of each component can be evenly spread across the specified topology domains.
Workload Controllers
Nebula Operator is going to support a variety of workload controllers. By configuring reference, you can choose a workload controller. Currently, besides the native StatefulSet, Nebula Operator supports the AdvancedStatefulSet feature provided by Community Edition of OpenKruise. Users can use the advanced features of Nebula Operator such as in-place upgrade and designating children nodes for a specific node to meet their own business needs. Of course, parameter configurations in Operator are necessary to enable these features. Currently, only parameters for in-place upgrade are available.
reference:
name: statefulsets.apps
version: v1
Other Functionalities
Other functionalities such as WebHook supporting configuration verification in high-availability mode and updating configuration of custom parameters are not introduced in this article. These features aim to allow Nebula Operator to manage NebulaGraph clusters more securely and conveniently on behalf of you. For more information, refer to the documentation on GitHub.
FAQ
Can Nebula Operator be used outside of Kubernetes?
No. Operator depends on Kubernetes. It is an extension of the Kubernetes API. It is a K8s tool.
How to ensure the stability and availability of upgrade and scaling? If the upgrade or scaling fails, can a cluster roll back?
We recommend that you back up your data before the operation to make sure that your cluster can roll back after a failure. At present, Nebula Operator does not support backing up data before the operation, but it will do after iterations.
Can I use Nebula Operator to manage a NebulaGraph v1.x cluster?
No. NebulaGraph v1.x does not support internal domain name resolution. Nebula Operator needs this feature, so it is not compatible.
Can the use of local storage ensure the stability of a cluster?
No guarantee now. If local storage is used, it means that Pods bind specific nodes, and currently, the Operator cannot fail over after a local storage node goes down. However, using network storage does not have such a problem.
When can Nebula Operator support the upgrade?
Nebula Operator needs to be in line with NebulaGraph. When NebulaGraph supports rolling upgrade, Nebula Operator will have this feature.
Nebula Operator is now open sourced and can be accessed via GitHub: https://github.com/vesoft-inc/nebula-operator.
Interested in Nebula Operator? Join the NebulaGraph Slack channel to discuss with the community!



