
FeaturesUse-cases
4 different ways to work with NebulaGraph in Apache Spark

A common question many NebulaGraph community users have asked is how to apply our graph database to Spark-based analytics. People want to use our powerful graph processing capabilities in conjunction with Spark, which is one of the most popular engines for data analytics.
In this article, I will try to walk you through four different ways that you can make NebulaGraph and Apache Spark work together. The first three approaches will use NebulaGraph’s three libraries: Spark Connector, Nebula Exchange, and Nebula Algorithm, whereas the fourth way will leverage PySpark, an interface for Spark in Python.
I have introduced quite a few data importing methods for NebulaGraph in this video, including three methods that import data to Spark. In this article, I’d like to dive deeper into these Spark-related projects, hoping it will provide more help if you want to connect NebulaGraph with Spark.
TL;DR
- Nebula Spark Connector is a Spark library to enable Spark applications to read from and write to NebulaGraph in the form of dataframes.
- Nebula Exchange, built on top of Nebula Spark Connector, is a Spark library and application to migrate different data sources like(MySQL, Neo4j, PostgreSQL, ClickHouse, Hive, etc.) to NebulaGraph. Besides writing directly to NebulaGraph, it can also optionally generate SST files to be ingested into NebulaGraph to offload the storage computation from NebulaGraph cluster to the Spark cluster.
- Nebula Algorithm, built on top of Nebula Spark Connector and GraphX, is a Spark library to run graph algorithms(PageRank, LPA, etc) on top of graph data from NebulaGraph.
- If you want to make Spark and NebulaGraph work together using Python, PySpark is the go-to solution, which I will cover in the last section.
Spark-Connector
Nebula Spark Connector is a Spark Lib to enable spark application reading from and writing to NebulaGraph in form of dataframe.
- Codebase: https://github.com/vesoft-inc/nebula-spark-connector
- Documentation: https://docs.nebula-graph.io/3.0.2/nebula-spark-connector/ (it's versioned, as for now, I put the lastest released version 3.0.2 here)
- Jar Package: https://repo1.maven.org/maven2/com/vesoft/nebula-spark-connector/
- Code Examples: example
Read data from NebulaGraph
In order to read data from NebulaGraph, Nebula Spark Connector will scan all storage instances in a NebulaGraph cluster that contain the given label(TAG). You can use the withLabel parameter to indicate the label. For example: withLabel("player"). You can also optionally specify the properties of the vertex: withReturnCols(List("name", "age")).
Once you have provided all required properties, you can run spark.read.nebula.loadVerticesToDF, which will return the dataframe of the vertex from NebulaGraph.
def readVertex(spark: SparkSession): Unit = {
LOG.info("start to read nebula vertices")
val config =
NebulaConnectionConfig
.builder()
.withMetaAddress("metad0:9559,metad1:9559,metad2:9559")
.withConenctionRetry(2)
.build()
val nebulaReadVertexConfig: ReadNebulaConfig = ReadNebulaConfig
.builder()
.withSpace("basketballplayer")
.withLabel("player")
.withNoColumn(false)
.withReturnCols(List("name", "age"))
.withLimit(10)
.withPartitionNum(10)
.build()
val vertex = spark.read.nebula(config, nebulaReadVertexConfig).loadVerticesToDF()
vertex.printSchema()
vertex.show(20)
println("vertex count: " + vertex.count())
}
It's similar for the writer part and one big difference here is the writing path is done via GraphD as underlying Spark Connector is shooting nGQL INSERT queries:
def writeVertex(spark: SparkSession): Unit = {
LOG.info("start to write nebula vertices")
val df = spark.read.json("example/src/main/resources/vertex")
df.show()
val config = getNebulaConnectionConfig()
val nebulaWriteVertexConfig: WriteNebulaVertexConfig = WriteNebulaVertexConfig
.builder()
.withSpace("test")
.withTag("person")
.withVidField("id")
.withVidAsProp(false)
.withBatch(1000)
.build()
df.write.nebula(config, nebulaWriteVertexConfig).writeVertices()
}
Hands-on Spark Connector
Prerequisites: I will assume that you are running the following procedure on a Linux machine with an internet connection. Ideally, you will have Docker and Docker Compose installed.
Bootstrapping a NebulaGraph cluster
Firstly, let's deploy NebulaGraph v3.0 and Nebula Studio using Nebula-Up, which will run a script to install the two tools using Docker and Docker Compose. The script will automatically install Docker and Docker Compose for you if you don’t already have them installed. But to make sure you get the best experience, you can pre-install Docker and Docker Compose on your machine manually.
curl -fsSL nebula-up.siwei.io/install.sh | bash -s -- v3.0
Once this is done, we can connect to the NebulaGraph instance with Nebula Console, the command line client for NebulaGraph.
- Enter the container with Nebula Console
~/.nebula-up/console.sh
- Connect to NebulaGraph
nebula-console -addr graphd -port 9669 -user root -p nebula
- Activate Storage Instances, and check hosts status
ref: https://docs.nebula-graph.io/3.0.2/4.deployment-and-installation/manage-storage-host/
ADD HOSTS "storaged0":9779,"storaged1":9779,"storaged2":9779;
SHOW HOSTS;
- Load the test graph data, which will take one or two minitues to finish.
:play basketballplayer;
Creating a Spark playground
It is very easy to create a Spark environment using Docker thanks to Big data europe, who provided a Spark docker image.
docker run --name spark-master-0 --network nebula-docker-compose_nebula-net \
-h spark-master-0 -e ENABLE_INIT_DAEMON=false -d \
-v ${PWD}/:/root \
bde2020/spark-master:2.4.5-hadoop2.7
Using this YMAL file, we will create a container named spark-master-0 with built-in hadoop 2.7 and spark 2.4.5. The container is connected to the NebulaGraph cluster in a docker network named nebula-docker-compose_nebula-net. It will also map the current path to /root of the spark container.
Then, we can access the Spark environment container with:
docker exec -it spark-master-0 bash
Optionally, we can install mvn inside the container to enable maven build/packaging:
docker exec -it spark-master-0 bash
# in the container shell
export MAVEN_VERSION=3.5.4
export MAVEN_HOME=/usr/lib/mvn
export PATH=$MAVEN_HOME/bin:$PATH
wget http://archive.apache.org/dist/maven/maven-3/$MAVEN_VERSION/binaries/apache-maven-$MAVEN_VERSION-bin.tar.gz && \
tar -zxvf apache-maven-$MAVEN_VERSION-bin.tar.gz && \
rm apache-maven-$MAVEN_VERSION-bin.tar.gz && \
mv apache-maven-$MAVEN_VERSION /usr/lib/mvn
which /usr/lib/mvn/bin/mvn
Run Spark Connector
In this section I will show you how to build the NebulaGraph Spark Connector from its soure code.
git clone https://github.com/vesoft-inc/nebula-spark-connector.git
docker exec -it spark-master-0 bash
cd /root/nebula-spark-connector
/usr/lib/mvn/bin/mvn install -Dgpg.skip -Dmaven.javadoc.skip=true -Dmaven.test.skip=true
Now let’s replace the example code:
vi example/src/main/scala/com/vesoft/nebula/examples/connector/NebulaSparkReaderExample.scala
In this file we will put the following code, where two functions readVertex and readEdges was created on the basketballplayer graph space:
package com.vesoft.nebula.examples.connector
import com.facebook.thrift.protocol.TCompactProtocol
import com.vesoft.nebula.connector.connector.NebulaDataFrameReader
import com.vesoft.nebula.connector.{NebulaConnectionConfig, ReadNebulaConfig}
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
import org.slf4j.LoggerFactory
object NebulaSparkReaderExample {
private val LOG = LoggerFactory.getLogger(this.getClass)
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf
sparkConf
.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.registerKryoClasses(Array[Class[_]](classOf[TCompactProtocol]))
val spark = SparkSession
.builder()
.master("local")
.config(sparkConf)
.getOrCreate()
readVertex(spark)
readEdges(spark)
spark.close()
sys.exit()
}
def readVertex(spark: SparkSession): Unit = {
LOG.info("start to read nebula vertices")
val config =
NebulaConnectionConfig
.builder()
.withMetaAddress("metad0:9559,metad1:9559,metad2:9559")
.withConenctionRetry(2)
.build()
val nebulaReadVertexConfig: ReadNebulaConfig = ReadNebulaConfig
.builder()
.withSpace("basketballplayer")
.withLabel("player")
.withNoColumn(false)
.withReturnCols(List("name", "age"))
.withLimit(10)
.withPartitionNum(10)
.build()
val vertex = spark.read.nebula(config, nebulaReadVertexConfig).loadVerticesToDF()
vertex.printSchema()
vertex.show(20)
println("vertex count: " + vertex.count())
}
def readEdges(spark: SparkSession): Unit = {
LOG.info("start to read nebula edges")
val config =
NebulaConnectionConfig
.builder()
.withMetaAddress("metad0:9559,metad1:9559,metad2:9559")
.withTimeout(6000)
.withConenctionRetry(2)
.build()
val nebulaReadEdgeConfig: ReadNebulaConfig = ReadNebulaConfig
.builder()
.withSpace("basketballplayer")
.withLabel("follow")
.withNoColumn(false)
.withReturnCols(List("degree"))
.withLimit(10)
.withPartitionNum(10)
.build()
val edge = spark.read.nebula(config, nebulaReadEdgeConfig).loadEdgesToDF()
edge.printSchema()
edge.show(20)
println("edge count: " + edge.count())
}
}
Then build it:
cd example
/usr/lib/mvn/bin/mvn install -Dgpg.skip -Dmaven.javadoc.skip=true -Dmaven.test.skip=true
Execute it on Spark:
/spark/bin/spark-submit --master "local" \
--class com.vesoft.nebula.examples.connector.NebulaSparkReaderExample \
--driver-memory 16g target/example-3.0-SNAPSHOT.jar
And the result should be like:
22/04/19 07:29:34 INFO DAGScheduler: Job 1 finished: show at NebulaSparkReaderExample.scala:57, took 0.199310 s
+---------+------------------+---+
|_vertexId| name|age|
+---------+------------------+---+
|player105| Danny Green| 31|
|player109| Tiago Splitter| 34|
|player111| David West| 38|
|player118| Russell Westbrook| 30|
|player143|Kristaps Porzingis| 23|
|player114| Tracy McGrady| 39|
|player150| Luka Doncic| 20|
|player103| Rudy Gay| 32|
|player113| Dejounte Murray| 29|
|player121| Chris Paul| 33|
|player128| Carmelo Anthony| 34|
|player130| Joel Embiid| 25|
|player136| Steve Nash| 45|
|player108| Boris Diaw| 36|
|player122| DeAndre Jordan| 30|
|player123| Ricky Rubio| 28|
|player139| Marc Gasol| 34|
|player142| Klay Thompson| 29|
|player145| JaVale McGee| 31|
|player102| LaMarcus Aldridge| 33|
+---------+------------------+---+
only showing top 20 rows
22/04/19 07:29:36 INFO DAGScheduler: Job 4 finished: show at NebulaSparkReaderExample.scala:82, took 0.135543 s
+---------+---------+-----+------+
| _srcId| _dstId|_rank|degree|
+---------+---------+-----+------+
|player105|player100| 0| 70|
|player105|player104| 0| 83|
|player105|player116| 0| 80|
|player109|player100| 0| 80|
|player109|player125| 0| 90|
|player118|player120| 0| 90|
|player118|player131| 0| 90|
|player143|player150| 0| 90|
|player114|player103| 0| 90|
|player114|player115| 0| 90|
|player114|player140| 0| 90|
|player150|player120| 0| 80|
|player150|player137| 0| 90|
|player150|player143| 0| 90|
|player103|player102| 0| 70|
|player113|player100| 0| 99|
|player113|player101| 0| 99|
|player113|player104| 0| 99|
|player113|player105| 0| 99|
|player113|player106| 0| 99|
+---------+---------+-----+------+
only showing top 20 rows
There are more examples under the Spark Connector repo, including one for GraphX. Please note that in GraphX it is assumed that the vertex ID is numeric, and you will need to convert string ID types into numeric on the fly. Please refer to the example in Nebula Algorithom on how to mitigate that.
Nebula Exchange
- Codebase: https://github.com/vesoft-inc/nebula-exchange/
- Documentation: https://docs.nebula-graph.io/3.0.2/nebula-exchange/about-exchange/ex-ug-what-is-exchange/ (it's versioned, as for now, I put the lastest released version 3.0.2 here)
- Jar Package: https://github.com/vesoft-inc/nebula-exchange/releases
- Configuration Examples: exchange-common/src/test/resources/application.conf
Nebula Exchange is a Spark library that can read data from multiple sources and write it to either NebulaGraph directly or a NebulaGraph SST Files.
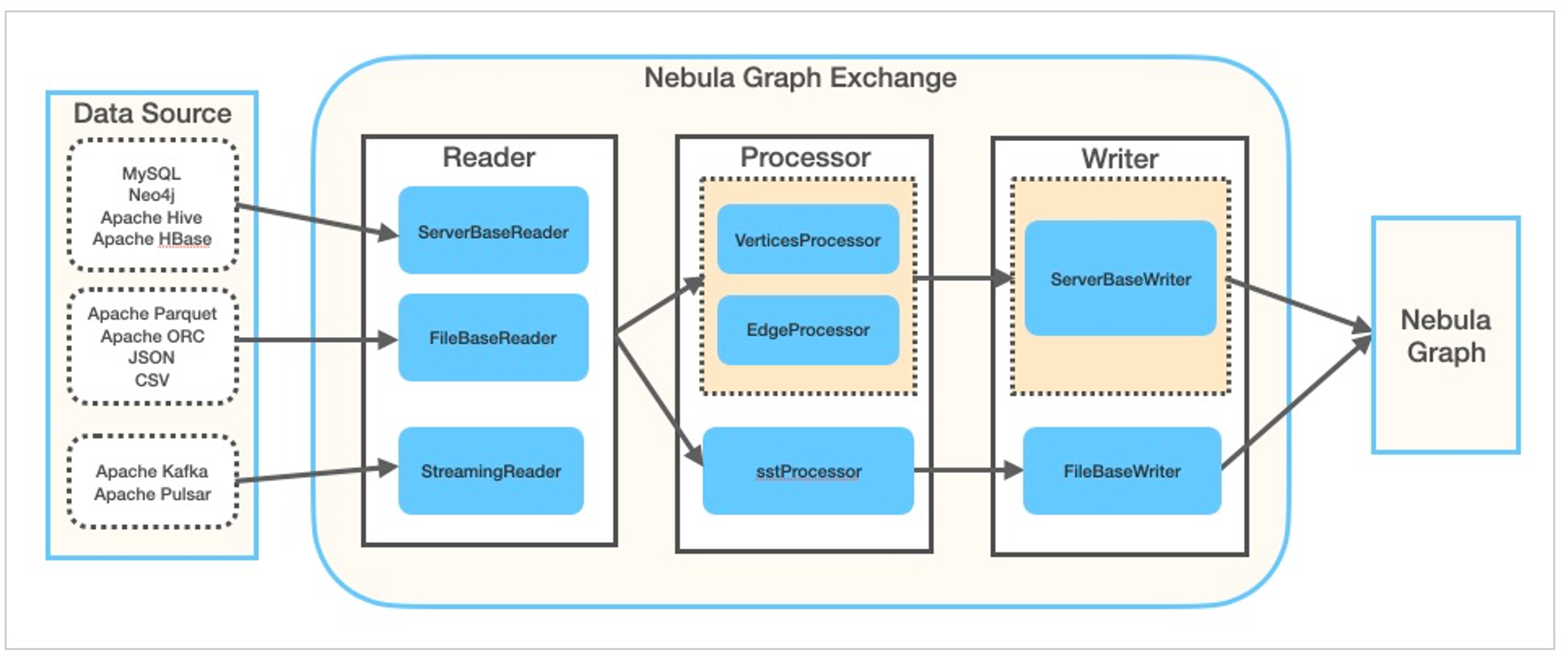
To use Nebula Exchange, we need to configure “where to fetch data sources” and “where to write graph data to” in a conf file, and submit the exchange package to spark with the conf file being specified.
Now let's do a hands-on test on Nebula Exchange with the same envrioment we created in previous chapter.
Hands-on Nebula Exchange
Here, we are using Nebula Exchange to consume data from a CSV file, in which the first column is the Vertex ID, and the second and third columns are "name" and "age", respectively.
player800,"Foo Bar",23
player801,"Another Name",21
- Let's log into the Spark container we created in previous chapter, and download the Jar package of Nebula Exchange:
docker exec -it spark-master bash
cd /root/
wget https://github.com/vesoft-inc/nebula-exchange/releases/download/v3.0.0/nebula-exchange_spark_2.4-3.0.0.jar
- Create a conf file named
exchange.confin theHOCONformat, where:- under
.nebula, information regarding NebulaGraph Cluster is configured; - under
.tags, information regarding Vertecies like how required fields are reflected to our data source(in this case, it's the CSV file) is configured.
- under
{
# Spark relation config
spark: {
app: {
name: Nebula Exchange
}
master:local
driver: {
cores: 1
maxResultSize: 1G
}
executor: {
memory: 1G
}
cores:{
max: 16
}
}
# NebulaGraph relation config
nebula: {
address:{
graph:["graphd:9669"]
meta:["metad0:9559", "metad1:9559", "metad2:9559"]
}
user: root
pswd: nebula
space: basketballplayer
# parameters for SST import, not required
path:{
local:"/tmp"
remote:"/sst"
hdfs.namenode: "hdfs://localhost:9000"
}
# nebula client connection parameters
connection {
# socket connect & execute timeout, unit: millisecond
timeout: 30000
}
error: {
# max number of failures, if the number of failures is bigger than max, then exit the application.
max: 32
# failed import job will be recorded in output path
output: /tmp/errors
}
# use google's RateLimiter to limit the requests send to NebulaGraph
rate: {
# the stable throughput of RateLimiter
limit: 1024
# Acquires a permit from RateLimiter, unit: MILLISECONDS
# if it can't be obtained within the specified timeout, then give up the request.
timeout: 1000
}
}
# Processing tags
# There are tag config examples for different dataSources.
tags: [
# HDFS csv
# Import mode is client, just change type.sink to sst if you want to use client import mode.
{
name: player
type: {
source: csv
sink: client
}
path: "file:///root/player.csv"
# if your csv file has no header, then use _c0,_c1,_c2,.. to indicate fields
fields: [_c1, _c2]
nebula.fields: [name, age]
vertex: {
field:_c0
}
separator: ","
header: false
batch: 256
partition: 32
}
]
}
- Finally, let's create the
player.csvandexchange.conffiles, which should be listed as follow:
# ls -l
-rw-r--r-- 1 root root 1912 Apr 19 08:21 exchange.conf
-rw-r--r-- 1 root root 157814140 Apr 19 08:17 nebula-exchange_spark_2.4-3.0.0.jar
-rw-r--r-- 1 root root 52 Apr 19 08:06 player.csv
- And we could call Exchange as:
/spark/bin/spark-submit --master local \
--class com.vesoft.nebula.exchange.Exchange nebula-exchange_spark_2.4-3.0.0.jar \
-c exchange.conf
And the result should be like:
...
22/04/19 08:22:08 INFO Exchange$: import for tag player cost time: 1.32 s
22/04/19 08:22:08 INFO Exchange$: Client-Import: batchSuccess.player: 2
22/04/19 08:22:08 INFO Exchange$: Client-Import: batchFailure.player: 0
...
Please refer to Nebula Exchange documentations and configuration examples for more data sources. For how to write Spark data into SST files, you can refer to both the documentation and Nebula Exchange SST 2.x Hands-on Guide (link in Chinese).
Nebula Algorithm
Built on top of Nebula Spark Connector and GraphX, Nebula Algorithm is an Spark library and application to run graph algorithms(pagerank, LPA etc…) on top of graph data in NebulaGraph.
- Codebase: https://github.com/vesoft-inc/nebula-algorithm
- Documentation: https://docs.nebula-graph.io/3.0.2/nebula-algorithm/ (it's versioned, as for now, I put the lastest released version 3.0.2 here)
- Jar Package: https://repo1.maven.org/maven2/com/vesoft/nebula-algorithm/
- Code Examples: example/src/main/scala/com/vesoft/nebula/algorithm
Calling with spark-submit
When we call Nebula Algorithm with spark-submit, on the how-to-run perspective, it is quite similar to Nebula-Exchange. This post comes with a hands-on example, too.
Calling Nebula Algorithm a library in code
We can also call Nebula Algorithm in Spark as a library. This approach will give you more control on the output format of the algorithm. Also, with this approach, it is possible to perform algorithm for non-numerical vertex ID types, see here.
PySpark for NebulaGraph
Finally, if you want to make Spark and NebulaGraph work together using Python, PySpark is the go-to solution. In this section, I will show you how to connect Spark and NebulaGraph using Nebula Spark Connector with the help of PySpark. PySpark is able to call Java or Scala packages inside Python, and it makes it very easy to use Spark Connector with Python.
Here I am doing this from the PySpark entrypoint in /spark/bin/pyspark, with Nebula Connector's Jar package specified with --driver-class-path and --jars
docker exec -it spark-master-0 bash
cd root
wget https://repo1.maven.org/maven2/com/vesoft/nebula-spark-connector/3.0.0/nebula-spark-connector-3.0.0.jar
/spark/bin/pyspark --driver-class-path nebula-spark-connector-3.0.0.jar --jars nebula-spark-connector-3.0.0.jar
Then, rather than pass NebulaConnectionConfig and ReadNebulaConfig to spark.read.nebula, we should instead call spark.read.format("com.vesoft.nebula.connector.NebulaDataSource").
Voilà!
df = spark.read.format(
"com.vesoft.nebula.connector.NebulaDataSource").option(
"type", "vertex").option(
"spaceName", "basketballplayer").option(
"label", "player").option(
"returnCols", "name,age").option(
"metaAddress", "metad0:9559").option(
"partitionNumber", 1).load()
>>> df.show(n=2)
+---------+--------------+---+
|_vertexId| name|age|
+---------+--------------+---+
|player105| Danny Green| 31|
|player109|Tiago Splitter| 34|
+---------+--------------+---+
only showing top 2 rows
I also made the same connection using Scala even though I almost have zero Scala knowledge. :-P
References:
def loadVerticesToDF(): DataFrame = {
assert(connectionConfig != null && readConfig != null,
"nebula config is not set, please call nebula() before loadVerticesToDF")
val dfReader = reader
.format(classOf[NebulaDataSource].getName)
.option(NebulaOptions.TYPE, DataTypeEnum.VERTEX.toString)
.option(NebulaOptions.SPACE_NAME, readConfig.getSpace)
.option(NebulaOptions.LABEL, readConfig.getLabel)
.option(NebulaOptions.PARTITION_NUMBER, readConfig.getPartitionNum)
.option(NebulaOptions.RETURN_COLS, readConfig.getReturnCols.mkString(","))
.option(NebulaOptions.NO_COLUMN, readConfig.getNoColumn)
.option(NebulaOptions.LIMIT, readConfig.getLimit)
.option(NebulaOptions.META_ADDRESS, connectionConfig.getMetaAddress)
.option(NebulaOptions.TIMEOUT, connectionConfig.getTimeout)
.option(NebulaOptions.CONNECTION_RETRY, connectionConfig.getConnectionRetry)
.option(NebulaOptions.EXECUTION_RETRY, connectionConfig.getExecRetry)
.option(NebulaOptions.ENABLE_META_SSL, connectionConfig.getEnableMetaSSL)
.option(NebulaOptions.ENABLE_STORAGE_SSL, connectionConfig.getEnableStorageSSL)
if (connectionConfig.getEnableStorageSSL || connectionConfig.getEnableMetaSSL) {
dfReader.option(NebulaOptions.SSL_SIGN_TYPE, connectionConfig.getSignType)
SSLSignType.withName(connectionConfig.getSignType) match {
case SSLSignType.CA =>
dfReader.option(NebulaOptions.CA_SIGN_PARAM, connectionConfig.getCaSignParam)
case SSLSignType.SELF =>
dfReader.option(NebulaOptions.SELF_SIGN_PARAM, connectionConfig.getSelfSignParam)
}
}
dfReader.load()
}
object NebulaOptions {
/** nebula common config */
val SPACE_NAME: String = "spaceName"
val META_ADDRESS: String = "metaAddress"
val GRAPH_ADDRESS: String = "graphAddress"
val TYPE: String = "type"
val LABEL: String = "label"
/** connection config */
val TIMEOUT: String = "timeout"
val CONNECTION_RETRY: String = "connectionRetry"
val EXECUTION_RETRY: String = "executionRetry"
val RATE_TIME_OUT: String = "reteTimeOut"
val USER_NAME: String = "user"
val PASSWD: String = "passwd"
val ENABLE_GRAPH_SSL: String = "enableGraphSSL"
val ENABLE_META_SSL: String = "enableMetaSSL"
val ENABLE_STORAGE_SSL: String = "enableStorageSSL"
val SSL_SIGN_TYPE: String = "sslSignType"
val CA_SIGN_PARAM: String = "caSignParam"
val SELF_SIGN_PARAM: String = "selfSignParam"
/** read config */
val RETURN_COLS: String = "returnCols"
val NO_COLUMN: String = "noColumn"
val PARTITION_NUMBER: String = "partitionNumber"
val LIMIT: String = "limit"
/** write config */
val RATE_LIMIT: String = "rateLimit"
val VID_POLICY: String = "vidPolicy"
val SRC_POLICY: String = "srcPolicy"
val DST_POLICY: String = "dstPolicy"
val VERTEX_FIELD = "vertexField"
val SRC_VERTEX_FIELD = "srcVertexField"
val DST_VERTEX_FIELD = "dstVertexField"
val RANK_FIELD = "rankFiled"
val BATCH: String = "batch"
val VID_AS_PROP: String = "vidAsProp"
val SRC_AS_PROP: String = "srcAsProp"
val DST_AS_PROP: String = "dstAsProp"
val RANK_AS_PROP: String = "rankAsProp"
val WRITE_MODE: String = "writeMode"
val DEFAULT_TIMEOUT: Int = 3000
val DEFAULT_CONNECTION_TIMEOUT: Int = 3000
val DEFAULT_CONNECTION_RETRY: Int = 3
val DEFAULT_EXECUTION_RETRY: Int = 3
val DEFAULT_USER_NAME: String = "root"
val DEFAULT_PASSWD: String = "nebula"
val DEFAULT_ENABLE_GRAPH_SSL: Boolean = false
val DEFAULT_ENABLE_META_SSL: Boolean = false
val DEFAULT_ENABLE_STORAGE_SSL: Boolean = false
val DEFAULT_LIMIT: Int = 1000
val DEFAULT_RATE_LIMIT: Long = 1024L
val DEFAULT_RATE_TIME_OUT: Long = 100
val DEFAULT_POLICY: String = null
val DEFAULT_BATCH: Int = 1000
val DEFAULT_WRITE_MODE = WriteMode.INSERT
val EMPTY_STRING: String = ""
}
- I learnt a lot from this talk
About the Author
Wey Gu is the Developer Advocate of NebulaGraph. He is passionate about spreading the graph technology to the developer community and trying his best to make distributed graph database more accessible. Follow him on Twitter or visit his blog for more fun stuff.



