Technical Deep Dives
May 25, 2026
Ontology and Graph Databases: Enterprise AI From Theory to Production Reality (Part II)
NebulaGraph
Part One Recap: The Theoretical Foundation
In Part One of this series, we introduced ontology as a 2,000-year-old philosophical discipline – an explicit specification of the entities, properties, relationships, and constraints within a domain.
We explained why ontology has become essential in the AI era: it grounds machine intelligence in deterministic semantics, eliminates data fragmentation, and provides the shared understanding that operational AI systems require.
We also demonstrated the natural affinity between ontology and graph databases, showing how enterprise platforms like NebulaGraph transform ontology from an abstract framework into a queryable, scalable, inference‑capable engine.
In short, Part One built the “why” – the theoretical case for ontology as the missing link in enterprise AI.
Synopsis – What This Post Covers
Data alone is not enough; you need semantic organization to make AI reliable. Ontology provides that layer.
Graph databases are the natural engine for operationalizing ontology, turning abstract definitions into queryable, enforceable business semantics.
Five warning signs indicate your enterprise urgently needs ontology: multi‑system fragmentation, high compliance demands, long decision chains, high data heterogeneity, and high inference cost.
Three domains are already adopting ontology at scale: platform enterprises, heavily regulated industries, and complex operational networks.
Ontology maturity follows four stages: business essence modeling → breaking data silos → knowledge iteration → intelligence‑driven enterprise brain.
Read on for the full breakdown, or jump directly to the section that interests you.
Why Data Alone Is Not Enough in the AI Era
Every executive today knows that data is valuable. But value is not automatic. In the AI era, the gap between having data and being data-driven has never been wider.
Most enterprises collect petabytes of information across dozens of siloed systems. Each system uses its own identifiers, its own naming conventions, and its own implicit assumptions. When a data scientist tries to train a model across these sources, the first 80% of the effort goes not into modeling but into data cleaning, entity resolution, and schema mapping.
This is the hidden tax of unorganized data. In a 2025 industry survey, 67% of enterprise AI leaders cited “data inconsistency and lack of semantic alignment” as their single largest barrier to production deployment.
The hard truth: data without semantics is noise. You can have perfect infrastructure, blazing-fast queries, and state-of-the-art models—but if your data lacks a shared, explicit definition of what things mean, your AI will remain unreliable and your insights will stay siloed.
What enterprises need is not more data. They need semantic organization—a layer that sits between raw data and AI applications, defining entities, relationships, and rules once, so that every model and every query inherits the same understanding.
That layer is ontology.
The Bridge Between Raw Data and Business Meaning
Ontology connects data to meaning by doing three things:
Naming things consistently. Instead of “cust_id” in one system and “client_number” in another, ontology declares a single canonical term: “CustomerID.” All systems map their local identifiers to this global concept.
Defining relationships explicitly. Ontology does not just list entities; it specifies how they interact. A Customer places an Order. An Order contains LineItems. A Product belongs to a Category. These relationships are typed, directed, and often constrained (e.g., “An Order must have at least one LineItem”).
Establishing inheritance and classification. A “PremiumCustomer” is a subclass of “Customer” and inherits all Customer properties, plus additional ones like “loyaltyTier” and “dedicatedAccountManager.”
This explicit semantic layer is the “ontology”. Ontology is not a separate document or a static diagram—it is a live, executable schema that shapes every data pipeline, every application, and every AI model. When a user queries the system, they are not querying raw tables; they are querying the ontology’s view of the world. This is why ontology has become a cornerstone of modern enterprise AI.
For different enterprises, the same principle applies. You need to recognize that your data already has implicit semantics—those implicit semantics are just inconsistent, undocumented, and fragile. Making them explicit is the first step toward scalable AI.
From Data to Stable Business Semantics Using Graph Models
How do you actually apply ontology to your data? The answer lies in graph modeling.
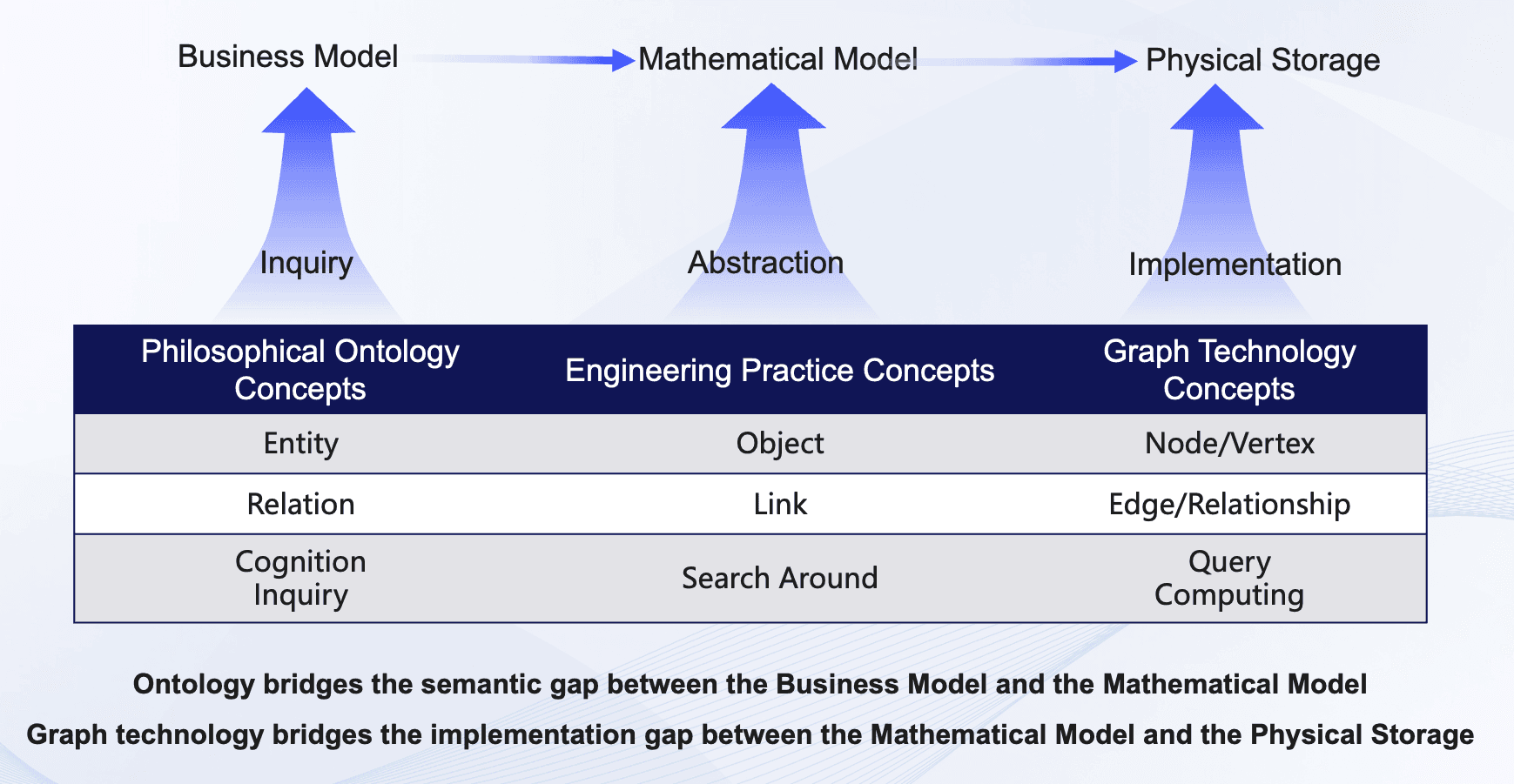
Graph Models as the Natural Ontology Language
Graph databases represent entities as nodes and relationships as edges. This is already an ontology-friendly structure. But to move from a generic graph to an ontology-driven graph, you need to add three things:
A type system. Every node has a label (e.g., “Customer,” “Product,” “Location”). Every edge has a type (e.g., “purchased,” “shipped_to,” “manufactured_by”). These types come directly from the ontology’s class definitions.
A property schema. Each node type defines which properties are required and optional. A “Customer” might require “customerID” and “registrationDate,” while “email” is optional. The database can enforce these constraints at write time.
Relationship constraints. The ontology specifies which relationships can exist between which types. A “Customer” can “place” an “Order.” A “Supplier” cannot. The graph database can validate this at insertion or at query time.
Once these three layers are in place, your raw data is no longer a collection of disconnected records. It becomes a semantic knowledge graph—a network where every entity knows its type, every relationship knows its meaning, and every query respects the ontology’s rules.
Building Stable Business Semantics
"Stability" is the key word. Without ontology, business semantics drift. A “customer” defined by marketing (anyone who has given an email) diverges from a “customer” defined by finance (anyone who has completed a paid transaction).
Ontology fixes this by creating a single source of semantic truth. The graph database enforces that truth at the storage and query layers. When a new application wants to ask “How many premium customers purchased a product last month?” It does not need to rediscover what “premium customer” means. The ontology defines it. The graph implements it. The answer is consistent across every dashboard, every report, and every model.
This is what it means to operationalize semantics: not just writing a document called “Data Dictionary,” but embedding meaning directly into the infrastructure.
Who Needs Ontology First?
Not every organization needs a full ontology-driven architecture tomorrow. But if your company exhibits three or more of the following five characteristics, ontology becomes a competitive necessity rather than a nice-to-have.
The Five Warning Signs
Sign | Description |
|---|---|
Multi-System | The same entity—a user, a product, a transaction—appears fragmented across dozens of applications, each with its own identifier and representation. |
High Compliance | Your industry demands explainable decisions. You cannot just give a conclusion; you must explain the relationships, decision paths, and accountability boundaries behind every outcome. |
Long Chain | Business logic depends on upstream and downstream dependencies. A single change in one system ripples unpredictably through event streams, rules, and processes. |
High Heterogeneity | Structured data, unstructured events, documents, and regulatory rules coexist. Traditional schemas cannot capture the variety without forcing unnatural structures. |
High Inference Cost | Humans can understand the connections—but every time a machine needs to answer a question, it has to “piece together the answer” from scattered sources, incurring massive engineering overhead. |
If your organization scores three or more on this list, you are likely already feeling the pain: slow time-to-insight, brittle integrations, and AI models that cannot be trusted for operational decisions.
Three Domains Where Ontology Is Already Unstoppable
The warning signs above cluster naturally into three broad industry categories that are urgently adopting ontology today:
Platform Enterprises – Think of Snapchat, major e-commerce, or social media platforms. They have millions or billions of users, content items, devices, and interactions. The same user appears across recommendation, advertising, fraud detection, and content moderation systems. Without a unified ontology, every new feature requires reintegrating the graph from scratch, and fraud rings exploit the cracks between systems.
Heavily Regulated Industries – Financial services, healthcare, and insurance must not only detect risks but also explain their decisions to regulators. A bank cannot simply flag a transaction as suspicious; it must trace the relationship chain between accounts, devices, and counterparties. Ontology provides the explicit relationship model that makes such explanations possible.
Complex Operational Networks – Supply chains, logistics, energy grids, and telecommunications. These environments involve long chains of dependencies—a part failure in one location affects downstream manufacturing, inventory, and customer shipments. Ontology enables root-cause analysis across the entire network in seconds, not days.
The common thread across these domains is that value lies in relationships, not individual records. And relationships become manageable only when they are explicitly defined and consistently enforced across every system.
The Four-Stage Maturity Journey: From Fragmentation to Intelligence
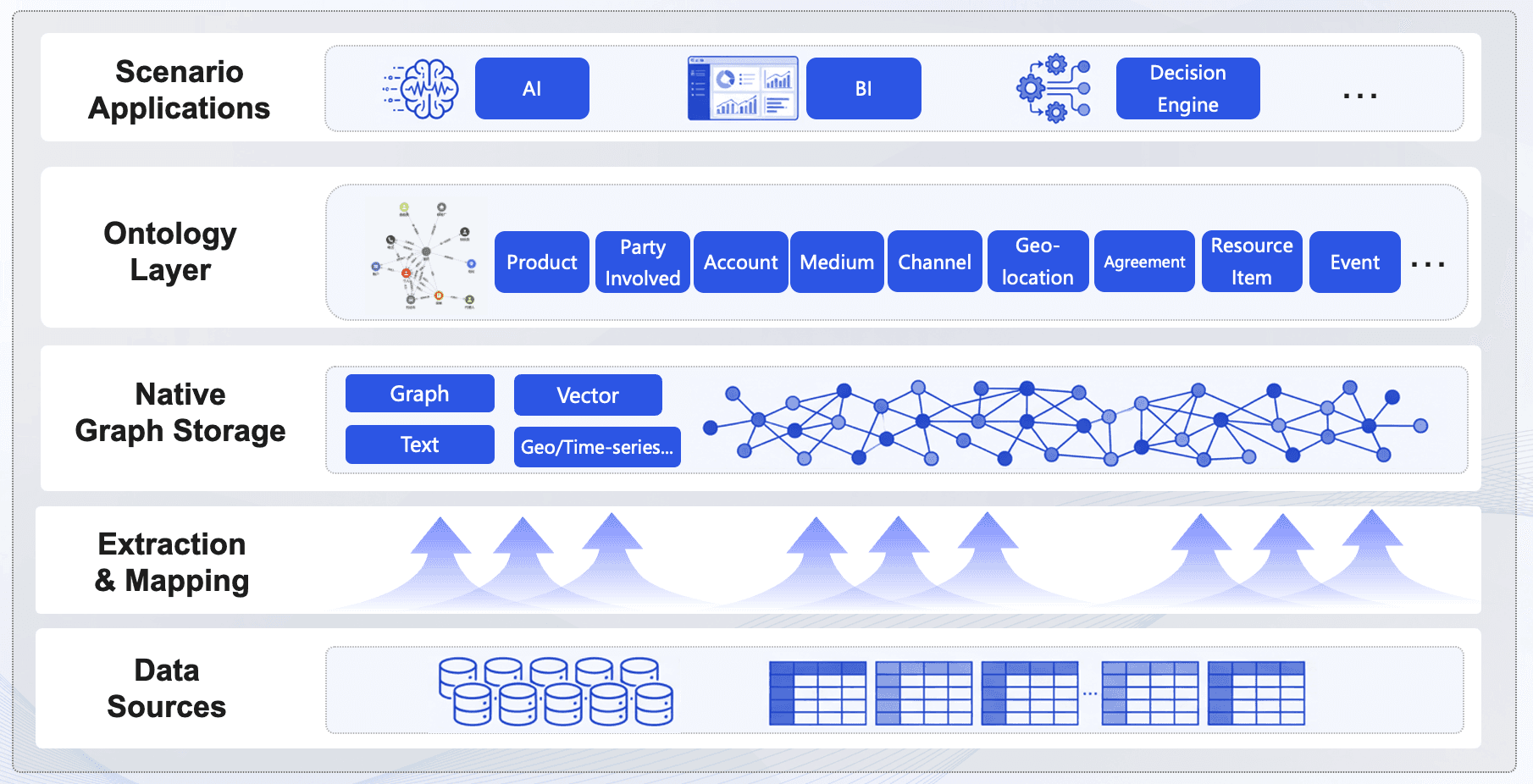
figure: Ontology Implementation Overall Architecture
Adopting ontology is not a one-time project. Based on real-world enterprise deployments, we have identified four distinct stages of ontology maturity. Understanding where you are today helps you plan your next step.
Stage 1: Business Essence Modeling
Focus: High-value business domain pilot.
In this stage, you select a single high-value domain—for example, customer identity, product hierarchy, or fraud detection—and build a local ontology. You identify core entities and their inherent relationships. You eliminate synonyms and homonyms within that domain. The goal is not enterprise-wide coverage but proving the concept on a bounded, impactful problem.
Key Actions:
Pilot conceptual modeling in a high-value business domain.
Eliminate polysemy (one term, multiple meanings) and synonyms (multiple terms, same meaning).
Outcome: A working ontology-backed application that demonstrates clear ROI. You now have a template for expansion.
Stage 2: Breaking Down Data Silos
Focus: Enterprise-wide ontology and data federation.
Once the pilot succeeds, you expand the ontology to cover the entire enterprise. This means modeling all core business entities and the canonical relationships between them. You then build data mapping pipelines that connect every source system—CRM, ERP, data lake, logs—to the ontology. Data starts flowing across previously siloed systems under a common semantic layer.
Key Actions:
Build an enterprise-wide ontology covering all core entities.
Establish automated data mappings; make data flow across physical silos.
Outcome: Cross-functional queries become possible without custom integration. A single ontology query can now return results that span marketing, sales, and supply chain data.
Stage 3: Knowledge Iteration
Focus: Deep relationship mining and automated knowledge completion.
With the ontology and graph populated, you now begin leveraging graph algorithms to discover what you don't yet know. Use community detection to find hidden customer segments. Use link prediction to infer missing relationships. Use label propagation to automate entity classification. The graph becomes a dynamic "enterprise knowledge brain" that continuously learns from new data.
Key Actions:
Apply deep-link queries, community analysis, link prediction, and label propagation.
Automate knowledge graph completion and refinement.
Enable continuous updates and fine-grained management of the knowledge system.
Outcome: The ontology no longer just reflects what you explicitly modeled—it surfaces implicit relationships and predictions that become new business insights.
Stage 4: Intelligence-Driven
Focus: The semantic layer as the enterprise AI brain.
At this final stage, the ontology-driven graph becomes the core reasoning engine for AI and automation. You connect large language models to the ontology, enabling precise, explainable enterprise Q&A—the LLM does not guess; it queries the deterministic ontology. You deploy inference rule engines that automatically detect hidden risks and business opportunities across the entire enterprise. And you establish closed-loop feedback: insights generated by AI are validated and then absorbed back into the ontology as new rules or relationship types.
Key Actions:
Integrate with LLMs to power accurate, explainable enterprise intelligent Q&A.
Configure inference rule engines for automated, enterprise-wide risk alerts and business insights.
Build closed-loop feedback: new knowledge from AI flows back into the ontology base.
Outcome: The ontology is no longer a static schema or even a knowledge graph—it is a living, learning "brain" that drives real-time decisions and continuously improves itself.
Most organizations start at Stage 1 or Stage 2. Reaching Stage 3 typically takes 12–18 months of focused investment. Stage 4 remains the frontier, but early adopters are already demonstrating dramatic improvements in decision speed and accuracy.
Conclusion: Turning Semantics into Competitive Advantage
We began this series with a simple observation: data without semantics is noise. In Part One, we laid out the theoretical case for ontology—its roots in philosophy, its relevance to AI, and its natural fit with graph databases. In Part Two, we have made the practical case.
Ontology is the missing layer that makes data operationally meaningful. We have shown how graph models transform ontology from a static document into a living, enforceable schema. We have identified the five warning signs that indicate your organization urgently needs ontology, and we have mapped the four-stage maturity journey from local pilot to enterprise AI brain.
The message for enterprise leaders is clear: you cannot scale AI without scaling semantics. Every new model, every real-time application, every cross-functional dashboard will eventually hit the wall of inconsistent data definitions. You can either keep building custom bridges between silos—each one expensive and fragile—or you can invest in an ontology-driven graph database that makes semantic consistency a platform feature, not a project.
The companies that win in the AI era will not be those with the most data. They will be those with the most organized data—data that speaks a common language, follows explicit rules, and connects meaningfully across every corner of the business.
Ready to Start Your Ontology Maturity Journey?
Whether you are at Stage 1, still struggling with multi-system fragmentation, or ready to jump to Stage 3, the path forward starts with the right graph database platform—one that supports explicit schema definitions, scales to billions of entities, and delivers millisecond queries in production.
Contact us to learn how NebulaGraph Enterprise Edition can help you operationalize ontology and turn your data into a strategic asset.
