Technical Deep Dives
Apr 23, 2026
What Is a Graph Database? A Complete Guide for 2026
NebulaGraph
The AI landscape has shifted dramatically over the past two years. Large language models (LLMs) have become remarkably good at pattern recognition and text generation. Yet there is a persistent challenge that developers and data architects continue to wrestle with: hallucination, lack of factual grounding, and the inability to reason across multi-hop relationships. LLMs are powerful pattern matchers, but they don’t truly understand the connections between entities—the relationships that define real-world systems.
This is where graph databases have entered the spotlight. In 2026, GraphRAG (graph-based retrieval-augmented generation) has emerged as one of the most promising architectures for grounding AI outputs in verifiable, connected knowledge. Major cloud providers are introducing graph-powered AI reasoning capabilities that translate natural language into graph queries, enabling LLMs to traverse relationship paths rather than relying on fragmented vector retrieval alone. The message is becoming clear: if you want AI to reason, you need to give it a map of how things connect.
But what exactly is a graph database? How does it work—and why should your organization consider adopting one? This post provides a comprehensive introduction to graph database technology, its core advantages, and the use cases where it delivers transformative value. For readers already familiar with the basics, we’ll also explore the critical distinction between graph storage and graph analytics—and how native graph solutions like NebulaGraph Database and NebulaGraph Analytics are built to handle both at massive scale.
What Is a Graph Database?
At its simplest, a graph database is a database management system designed to store, query, and navigate interconnected data. Unlike traditional relational databases that store information in rigid tables and reconstruct relationships using expensive JOIN operations, graph databases treat relationships as first-class citizens—they are stored directly alongside the data itself.
A graph database uses two fundamental building blocks:
Nodes (or vertices): Represent entities—people, products, locations, transactions, or any object you want to track.
Edges (or relationships): Represent the connections between nodes—such as “follows,” “purchased,” “located_in,” or “transfers_to.”
Each node and edge can also carry properties (key-value pairs) that provide additional context. For example, a Personnode might have properties like name, age, and email, while a transfers_to edge might include amount, timestamp, and currency.
This data model is remarkably intuitive because it mirrors how humans naturally think about relationships. A social network, a supply chain, a fraud ring, or a corporate knowledge graph—all are networks of connected entities. Graph databases capture that structure natively.
Why “graph”? The term comes from graph theory in mathematics, which studies networks of vertices connected by edges. A graph database is essentially a practical implementation of this mathematical concept for real-world data management.
How Do Graph Databases Work?
To understand how a graph database works, it helps to contrast it with the relational database model that most data professionals know well.
In a relational database: You store data across multiple tables, each representing an entity type (e.g., Customers, Orders, Products). Relationships are expressed through foreign keys—a column in one table that references a primary key in another table. To retrieve connected data, the database engine performs JOIN operations to stitch these tables back together at query time.
This approach works well for structured, moderately connected data. But as the number of JOINs grows, query performance degrades exponentially. A query that traverses five levels of relationships might require dozens of JOINs and become prohibitively slow at scale.
In a graph database: Relationships are stored explicitly as edges, directly connecting nodes. To retrieve connected data, the database performs traversal queries that follow these edges from one node to the next, much like clicking hyperlinks on the web. Because the relationship is already there—stored and indexed—there is no need for expensive JOINs. The query speed is proportional only to the number of nodes and edges visited, not the total size of the dataset.
This architectural difference has profound implications for real-time applications. A query that would take seconds or minutes in a relational database can often execute in milliseconds on a properly designed graph database, especially as relationship depth increases.
Graph Query Languages
Graph databases are queried using specialized languages designed for pattern matching and path traversal. Common languages include:
Cypher (originally developed for Neo4j): A declarative, SQL-inspired language for graph pattern matching.
Gremlin: A graph traversal language from the Apache TinkerPop project.
GQL (Graph Query Language): The ISO-standard graph query language, adopted in 2024, representing the first new ISO database language since SQL.
NebulaGraph Enterprise stands as the first distributed graph database to offer native GQL support, providing enterprise users with standardized, interoperable query capabilities and enhanced data compatibility.
Graph Algorithms in Practice
Beyond basic queries, graph databases enable powerful graph analytics through specialized algorithms that analyze relationships and behaviors. Common algorithms include:
Pathfinding (shortest path, all-pairs shortest path): Essential for logistics, routing, and network optimization.
Centrality analysis (PageRank, betweenness centrality): Identifies influential nodes, critical connectors, or single points of failure.
Community detection (Louvain, Label Propagation): Reveals clusters, social groups, or fraud rings.
Similarity measurement: Finds related entities based on connection patterns.
These algorithms allow organizations to move from simply “storing connections” to “deriving intelligence from connections”—a shift that is increasingly critical as AI systems demand deeper contextual understanding.
When to Use a Graph Database (Key Application Scenarios)
Graph databases are not a universal replacement for relational databases. They excel in specific scenarios where relationships are the primary value of the data. Here are the most impactful use cases.
Fraud Detection and Anti-Money Laundering
Financial fraud is inherently relational. A suspicious transaction is rarely an isolated event—it connects to accounts, devices, IP addresses, and other transactions in a network. Graph databases excel at uncovering hidden patterns that would be invisible to traditional analytics: circular money flows, shared identity attributes across seemingly unrelated accounts, or unusually dense clusters of transactions.
In a graph-based fraud detection system, a compliance officer can traverse from a suspicious transaction through multiple hops to discover a full fraud ring in real time.
Recommendation Engines and Personalization
Modern recommendation systems need to consider multiple factors: what a user has purchased, what similar users have purchased, what products are frequently bought together, and what content a user has engaged with recently. Graph databases model these multi-faceted relationships naturally, enabling real-time personalized recommendations without precomputed batch jobs.
Knowledge Graphs for AI and Search
Enterprise knowledge graphs are among the fastest-growing graph database applications. By connecting disparate data sources into a unified graph, organizations can enable semantic search, intelligent assistants, and AI-powered question-answering systems that understand context and relationships, not just keyword matches.
Supply Chain and Logistics
From route optimization to inventory tracking, supply chains are fundamentally networks of suppliers, warehouses, products, and transportation routes. Graph databases help logistics companies find optimal paths, identify single points of failure, and trace product provenance across multi-tier supply chains.
Social Networks and Identity Management
Social platforms are the typical graph use case: users, their connections, shared interests, group memberships, and content interactions all form a complex web. Graph databases power friend recommendations, feed ranking, influence analysis, and community detection in modern social platforms.
Network and IT Operations
Telecommunications and IT infrastructure are graphs of devices, connections, dependencies, and services. Graph databases enable root-cause analysis, impact assessment, and anomaly detection across complex network topologies.
Smart Grid
Modern power grids are dynamic networks of substations, transformers, meters, and renewable sources. Graph databases model grid topology, track energy flow, detect outage propagation, and optimize load balancing—all in real time.
Advantages of Graph Databases
The global graph database market is growing at over a 24% CAGR (compound annual growth rate), projected to reach nearly $5 billion in 2026. Why would an organization choose a graph database over a relational or other NoSQL solution? The advantages fall into several key categories.
Performance for Connected Queries
Graph databases are dramatically faster for relationship-heavy queries. As query depth increases, the performance gap widens. A graph database can execute a 5-hop path query in milliseconds, while the equivalent relational query might take seconds or minutes.
Flexible and Agile Data Modeling
The graph data model is inherently schema-flexible. Adding a new relationship type or node property does not require altering tables, rewriting queries, or performing expensive migrations. This agility is crucial in fast-moving domains where data requirements evolve continuously.
Intuitive Representation of Real-World Relationships
Graph databases model data the way business users think about it. This natural alignment reduces the cognitive gap between problem domain and technical implementation, accelerating development and reducing misinterpretation.
Scalability for Massive Graphs
Modern graph databases are designed for horizontal scalability. Native distributed graph databases like NebulaGraph can scale to trillions of edges across clusters, storing and querying graphs that would be impossible for traditional systems to handle.
Real-Time Query Response
Graph databases support real-time queries with millisecond latency, making them suitable for operational applications like fraud detection, real-time recommendations, and live personalization.
Graph Database and Graph Analytics: From Storage to Intelligence
It is important to distinguish between two related but distinct capabilities: graph storage (what a graph database does by default) and graph analytics (deriving insights through computation).
Most graph databases are optimized for transactional workloads—point queries, short traversals, and real-time lookups. They store the graph efficiently and retrieve small subgraphs quickly. However, running large-scale analytical algorithms—global PageRank, community detection across billions of nodes, or custom fraud scoring logic—is a different class of problem.
Traditional challenges with graph analytics include:
Off-the-shelf algorithms rarely map perfectly to unique business problems.
Business logic for risk detection or anti-money laundering is often proprietary—outsourcing its implementation is not an option.
The cycle time for algorithm iteration (from business need to production deployment) can stretch to weeks or months, creating unacceptable delays in fast-moving threat environments.
How NebulaGraph Approaches Graph Storage
NebulaGraph is a native, distributed graph database architected from the ground up for scale. Unlike multi-model databases that bolt graph capabilities onto existing storage engines, native graph databases are specifically optimized for graph storage and processing. This design philosophy yields significant advantages in query performance, scalability, and efficiency.
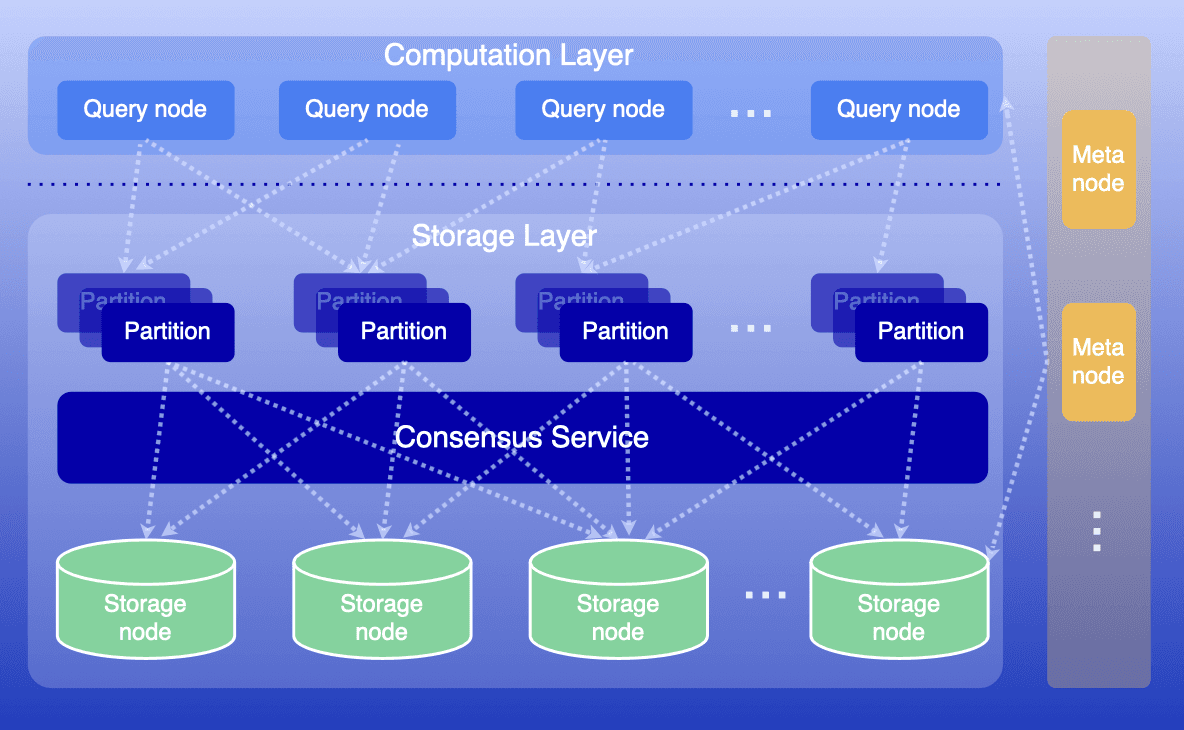
NebulaGraph can host graphs with billions of vertices and edges, serving queries with millisecond latency. Its shared-nothing distributed architecture enables linear horizontal scalability, meaning you can grow your graph infrastructure as your data grows—without performance cliffs or painful migrations.
NebulaGraph Analytics: Custom Graph Computation at Scale
NebulaGraph Analytics is a dedicated graph analytics solution designed to run complex, custom algorithms directly on massive graph workloads. Its core philosophy is straightforward: organizations should not be limited to pre-packaged algorithms. They should be able to write, modify, and deploy their own analytical logic—in hours, not weeks.
The cornerstone of NebulaGraph Analytics is its support for GQL-based custom algorithm development. NebulaGraph Analytics allows users to define algorithms using GQL—the same declarative language used to query the graph itself. This creates a unified semantic environment where business users can focus on the what (business logic) rather than the how (distributed computing frameworks).
In essence, NebulaGraph Analytics adds a powerful graph computation layer on top of your existing data ecosystem, enabling insights without the friction of complex data migration.
Here to learn more about NebulaGraph Analytics: Billion-Relation Analytics in the AI Era: NebulaGraph Analytics
Conclusion: Why Graph Databases Matter in the AI Era
Graph databases have evolved from a niche technology to a mainstream data management solution. Their ability to store, query, and analyze relationships natively and in real-time makes them indispensable for applications where connections matter as much as the data itself.
Graph Analytics utilizes the underlying graph database to run complex, custom algorithms directly on massive graph workloads -- often in an off-line environment. The ability to develop custom, use-case specific algorithms and deploy their own analytical logic is paramount to delivering business results.
As AI systems increasingly rely on GraphRAG and knowledge-grounded reasoning, graph databases are becoming a foundational layer of the AI stack. They provide the structured, verifiable relationship data that LLMs need to move beyond pattern matching and toward genuine understanding.
Ready to Explore Graph Technology for Your Organization?
If you are evaluating graph databases for fraud detection, knowledge graphs, real-time recommendations, or AI-powered applications, NebulaGraph offers a native, distributed platform designed for scale. From billions of edges to millisecond query latency, NebulaGraph is built for production workloads.
Contact our team to discuss your use case, request a demo, or download the technical brochure: 👉 https://nebula-graph.io/contact
Further Reading
What is a Graph Database and What are the Benefits of Graph Databases
Database Selection: Critical Factors for Modern Applications
Vector Database vs. Graph Database: What Is Better for Your Project
Why Graph Databases Like NebulaGraph Are Essential for the Next Generation of AI and LLMs
NebulaGraph 2025 Year in Review: Charting a New Era of Graph Intelligence and AI Convergence
