This post describes in detail how to deploy a NebulaGraph cluster with Docker Swarm.
Deploy a NebulaGraph Cluster
2.1 Environment Preparation
Prepare hosts as below.
ip
Memory (GB)
CPU (# of Cores)
192.168.1.166
16
4
192.168.1.167
16
4
192.168.1.168
16
4
Please make sure that Docker has been installed on all the machines.
2.2 Initialize the Swarm Cluster
Execute the commands below on the host 192.168.1.166:
2.3 Add a Worker Node
Add a Swarm worker node per the notification message of the init commands. Execute the following commands on 192.168.1.167 and 192.168.1.168 respectively.
Edit the nebula.env file by adding the items below:
2.6 Start the NebulaGraph Cluster
Cluster Configuration for Load Balancing and High Availability
The NebulaGraph clients (1.X) don't provide load balancing capability currently. They randomly select any graphd to connect the database. Therefore, you need to configure load balancing and high availability on your own if you want to use NebulaGraph in production.
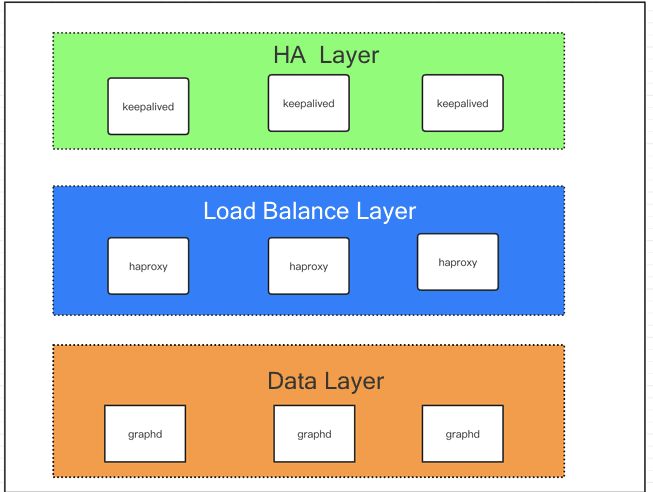
Seen from the figure above, the entire deployment can be divided into three layers, i.e. data layer, load balance layer, and high availability layer.
The load balance layer is responsible for distributing the requests from the client to the data layer for load balancing purpose.
The HA layer is realized by HAProxy and it ensures that the load balancing service works properly so that the entire cluster works properly.
3.1 Load Balancing Configuration
HAProxy uses Docker compose for configuration. Edit the three files below respectively:
Follow the configuration steps on 192.168.1.166, 192.168.1.167, and 192.168.1.168.
Install Keepalived
Modify Keepalived's configuration file, i.e. /etc/keepalived/keepalived.conf. Note that the priority item should be set to different values for the three hosts so that there is a priority among them.**
Note: Please be noted that vip (virtual IP) is required to configure Keepalive. In the configurations below, 192.168.1.99 is the virtual IP.
a. Configuration on 192.168.1.166
global_defs {router_id lb01 #Anidentifier;}vrrp_script chk_haproxy {script "killall -0 haproxy"interval 2}vrrp_instance VI_1 {state MASTERinterface ens160virtual_router_id 52priority 999
# Set the interval(inseconds)forsync check between MASTER and BACKUP load balancers.
advert_int1
# Configure the authentication type and passwordauthentication {
# Configure the authentication type,mainly PASS and AHauth_type PASS
# Set the authentication password.TheMASTER and BACKUP load balancers must use the same password within the same vrrp_instance to communicate properly.
auth_passamber1}virtual_ipaddress {
# The virtual IP is 192.168.1.99/24;Bounded interface is ens160;Alias forboth MASTER and BACKUP load balancers is ens160:1192.168.1.99/24dev ens160 label ens160:1}track_script {chk_haproxy}}
b. Configuration on 192.168.1.167
global_defs {router_id lb01 #Anidentifier;}vrrp_script chk_haproxy {script "killall -0 haproxy"interval 2}vrrp_instance VI_1 {state BACKUPinterface ens160virtual_router_id 52priority 888
# Set the interval(inseconds)forsync check between MASTER and BACKUP load balancers.
advert_int1
# Configure the authentication type and passwordauthentication {
# Configure the authentication type,mainly PASS and AHauth_type PASS
# Set the authentication password.TheMASTER and BACKUP load balancers must use the same password within the same vrrp_instance to communicate properly.
auth_passamber1}virtual_ipaddress {
# The virtual IP is 192.168.1.99/24;Bounded interface is ens160;Alias forboth MASTER and BACKUP load balancers is ens160:1192.168.1.99/24dev ens160 label ens160:1}track_script {chk_haproxy}}
c. Configuration on 192.168.1.168
global_defs {router_id lb01 #Anidentifier;}vrrp_script chk_haproxy {script "killall -0 haproxy"interval 2}vrrp_instance VI_1 {state BACKUPinterface ens160virtual_router_id 52priority 777
# Set the interval(inseconds)forsync check between MASTER and BACKUP load balancers.
advert_int1
# Configure the authentication type and passwordauthentication {
# Configure the authentication type,mainly PASS and AHauth_type PASS
# Set the authentication password.TheMASTER and BACKUP load balancers must use the same password within the same vrrp_instance to communicate properly.
auth_passamber1}virtual_ipaddress {
# The virtual IP is 192.168.1.99/24;Bounded interface is ens160;Alias forboth MASTER and BACKUP load balancers is ens160:1192.168.1.99/24dev ens160 label ens160:1}track_script {chk_haproxy}}