Case Studies
Jun 27, 2022
Graph Database For Recommendation Systems
Wayne Sheng
Real-time recommendation is a very popular topic in the retail industry. The goal of real-time recommendation is to provide personalized recommendations for users immediately after they search for products on e-commerce websites. It is a challenging task since the user has not yet decided which product they want to buy, so it requires a deep understanding of their preferences and behaviors.
In order to achieve this goal, real-time recommender systems need to be able to process big data at near real-time speed. Real-time systems are often used as part of e-commerce websites or mobile apps, where they can recommend products based on what the user is currently doing. For example, if an e-commerce site is selling shoes, it might want to show the user different styles of shoes when they are looking at the "men's sneakers" page.
Graph technology is a good choice for real-time recommendation. It has the ability to predict user behavior and make recommendations based on it. Graph databases like NebulaGraph provide a flexible data model that allows you to represent any kind of relationship between entities. This includes not only the typical "product" and "user" relationships, but also any other relationships that are important to your application. For example, you can use a graph database to represent complex groupings of users (such as "friends") or categories of products (such as "books"). As long as there's an edge between two entities, you can use graph technology.
The ability to represent any kind of relationship also makes it possible for graph databases to be more expressive than relational databases. For example, if you have a large number of users who share similar interests but belong to different groups, then in relational databases this might mean having a separate table for each group and then joining them together into one big table at query time. In contrast, in a graph database, it would be possible for each user to have multiple edges representing their interests in different groups.
What is a graph database?
A graph is known as a diagram that illustrates a relationship between two things. Thus, a graph database can be assumed to be a database to understand relationships between data.
Graph databases are unlike traditional Relational Database Management Systems (RDBMSs) most people are familiar with. RDBMSs house data in a table of columns and rows with little or no relation to each other.
Graph databases are fundamentally designed with a focus on the relationship between data sets. So, they require more intense and specialized processing capabilities. As a result, graph databases like NebulaGraph use sophisticated design and architecture.
Graph databases are designed to uncover important relationships between many big data sets. In other words, it can connect the dots between multiple datasets that might otherwise just be sitting useless in silos. And graph databases are already widely used for such purposes.
What is a real-time recommender system?
recommender systems are used to predict customer preferences and provide them with products or services that they might like. It helps companies reduce costs and increase revenues by providing personalized recommendations for their customers.
Recommender systems are used in a variety of industries including retail, media and entertainment, travel, and the public sector.
For example, Netflix uses an algorithm to recommend movies based on what you’ve watched previously. Amazon uses recommendations to help shoppers find new products they might be interested in purchasing. And Facebook uses its own algorithm to show you relevant ads based on your interests and likes.
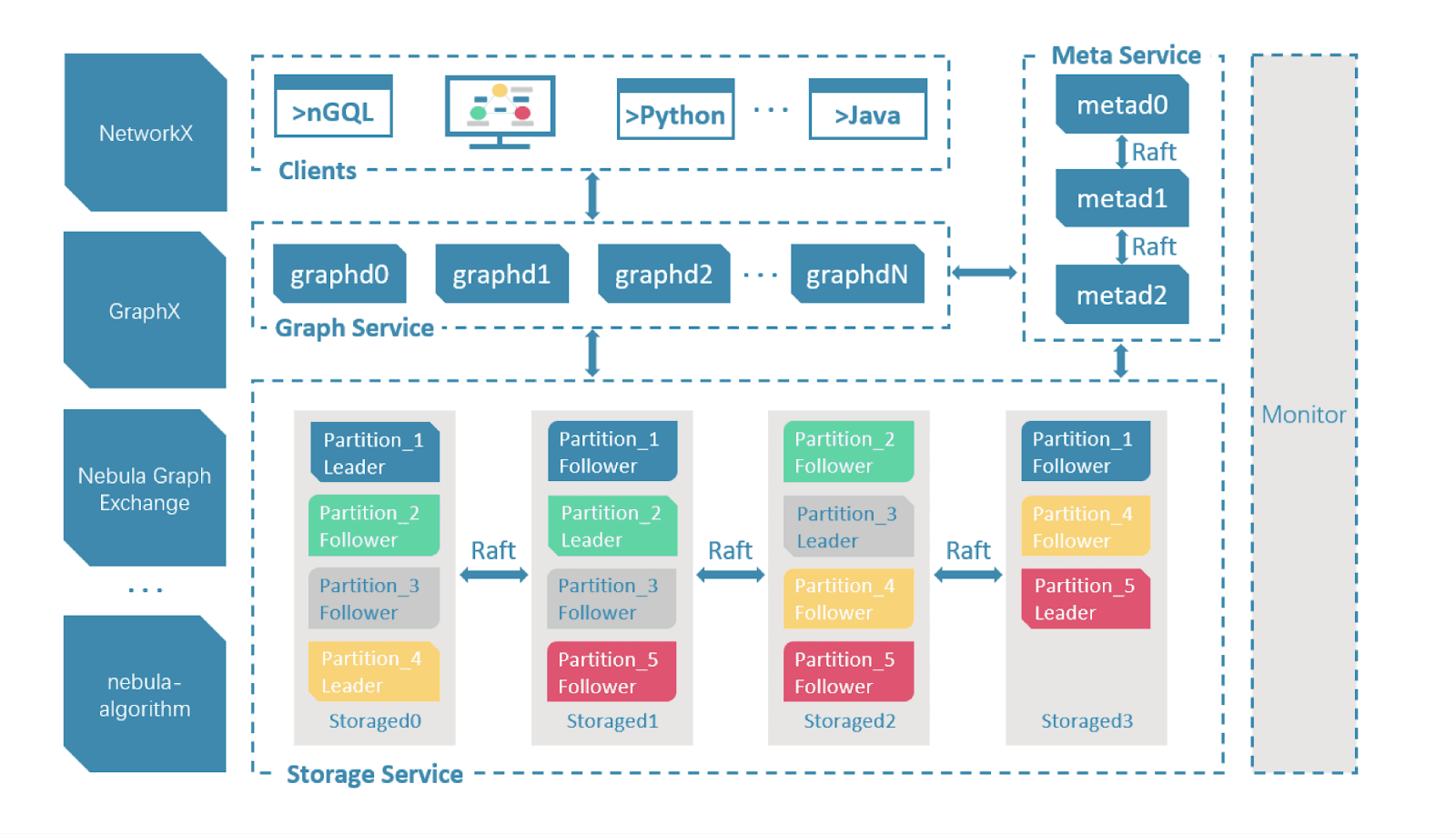
Why should you use NebulaGraph database for real-time recommendation?
NebulaGraph is a highly performant linearly scalable graph database available for use via a shared-nothing distributed model. In several real production environments, data mining and technical performance has been proven to beat the performance of competing graph databases by multiple times over.
The goal behind NebulaGraph is to unleash the power of exponentially growing connected data.
NebulaGraph securely processes data sets of at least twice the size and twice as fast as any competing graph databases
It is the only database that can store and process billions of data points with trillions of relational connections
NebulaGraph is designed for scalability and recovery without disruption, ensuring the best business continuity available
How graph technology is used in recommendation systems
Recommender systems aim to provide users with personalized recommendations based on their tastes and preferences. The characteristics of a user can be represented by their preferences for movies and books, for example, or their shopping habits on an e-commerce website. There are two main types of recommender systems: 1) collaborative filtering methods and 2) model-based methods.
A collaborative filtering method, such as KNN, can predict the movie rating without knowing the attributes of the movies and users. To address this challenge, the graph factorization approach combines the model-based method with the collaborative filtering method to improve prediction accuracy when the rating record is sparse.
Graph factorization methods have been widely used in many online recommender systems. Graph factorization is a graph-based model that can be used to represent user preferences as well as the relationship between users, items, and attributes. The goal of graph factorization is to extract the latent features from user ratings and recommendations so that these features can be used to predict users' preferences in an unsupervised manner.
Graph factorization is done by breaking down the original dataset into smaller datasets or clusters. This process can be done using graph databases because they are designed to support highly connected data structures and relationships between data points.
How to build a recommender system using NebulaGraph database
If you want to build your own recommender system, there are many different approaches you can take. One of the most popular is using a graph database like NebulaGraph. This section will walk through how to build a recommender system using a graph database.
Define the data model
In this step, we define the data model for our recommender system. The first thing we need to define is what type of data can be recommended. For example, we want to recommend movies so we will use movies as our entity. The second thing is what kind of information do we need about a movie? For example, if you are building a recommender system for books, maybe you need to know what genre it belongs to or what language it was written in. But in our case, all we need is the title, the year of release, the genre, and the country. So our movie entity is defined like this:

Define relationships
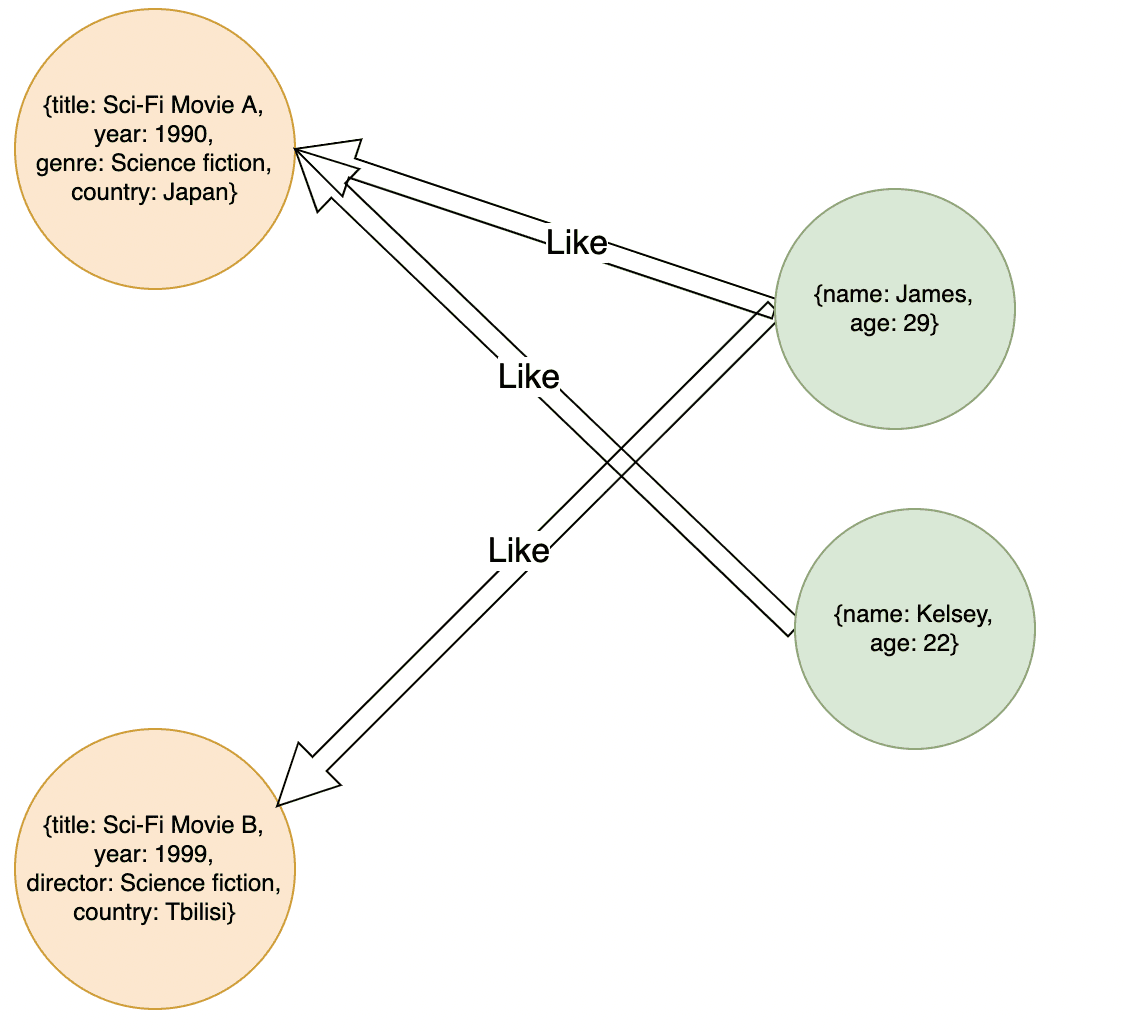
The next thing we need to do is define what type of relationship exists between movies and users (or people). There are two types of relationships that exist between movies and users: user likes movie and user has watched movie (or user has not watched movie). In this example, we will simplify it to just user likes movie.
Now imagine two users James and Kelsey, who are both fans of Sci-Fi Movie A, which has a genre of Science fiction. James also likes Sci-Fi Movie B, but Kelsey hasn’t watched it, so we don’t know whether Kelsey likes it or not.
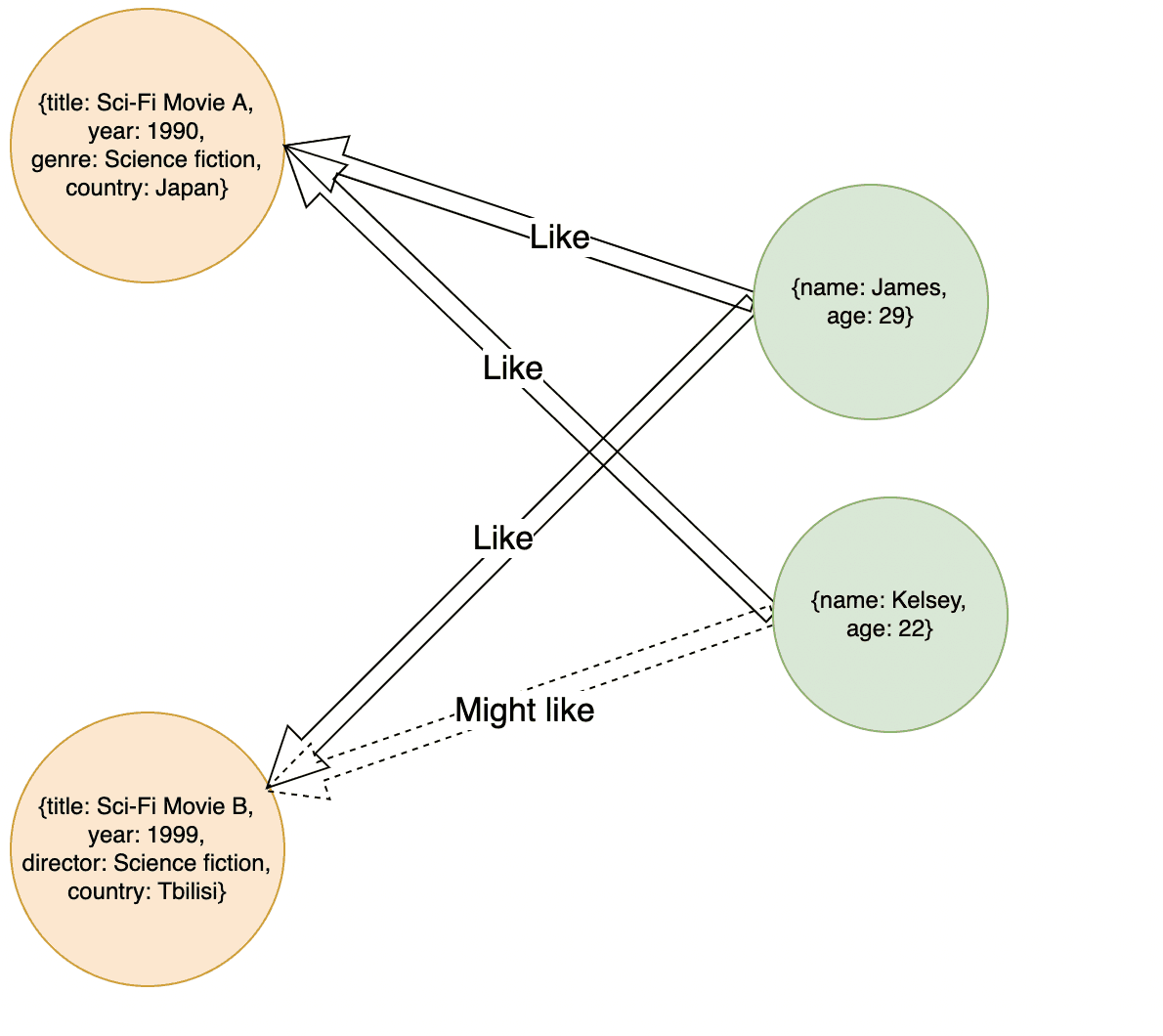
But using this graph modeling of data, we may easily find out that Kelsey may like Sci-Fi Movie B. The recommender system would recommend Sci-Fi Movie B to Kelsey because James — who likes the same things as Kelsey — likes Sci-Fi Movie B.
Making recommendations
There are a few graph algorithms that you can use to make recommendations within a graph database.
The PageRank algorithm: The PageRank algorithm is used to rank web pages in search results. The purpose of this algorithm is to determine which web pages should be displayed first when someone searches Google or any other major search engine.
The basic idea behind PageRank is that if you link to another page, then that page is more important than your own page. So if you are linking to a page about shopping for shoes, and someone else links to your shoe shopping site, then that person thinks your site is more important than it really is.
If everyone is linking to the same sites, then the people who link most get more weight.
Continuing with the movie analogy, while watching movies one can either carry on watching movies of a similar genre (and hence follow their most expected journey), or skip to a random movie in a totally different genre. It turns out that this is exactly how Google ranks websites by popularity using the PageRank**_ _**algorithm.
The popularity of a website is measured by the number of links it points to (and is referred from). In our movie use case, the popularity is built as the number hashes a given movie shares with all its neighbors.
Collaborative filtering: Collaborative Filtering (CF) is a method for recommender systems based on information regarding users, items, and their connections. Recommendations are made by looking at the neighbors of the user at hand and their interests. Since they are similar, the assumption is made that they share the same interests.
Read more: Build a Recommendation Engine With Collaborative Filtering
Conclusion
In conclusion, it's worthwhile to use graph databases to build real-time recommender systems. Since graph databases are well designed for representing the relationship among users and products in the recommender system, they can be used to build real-time recommendation systems. Graph databases' support of powerful data analysis makes it useful in constructing recommender systems that need to take into account users and products with different preferences.
