Case Studies
Nov 30, 2022
Graph Data Modeling and ETL with dbt in NebulaGraph Database
Wey Gu
How could we model data in Tabular sources and ETL it to NebulaGraph? This article demostrate us an end-to-end example doing so with dbt.
Task
Imagine we are building a Knowledge Graph for a content provider web service with NebulaGraph, thus leveraging it to support a Knowledge Base QA system, Recommendation System, and Reasoning system.
The knowledge information persisted in different data sources from some Service APIs, Databases, Data Warehouses, or even some files in S3.
We need to:
Analyze data to extract needed knowledge
Model the Graph based on relationships we care
Extract the relationships and ingest them to NebulaGraph
Data Analysis
Assume that we are fetching data from OMDB and MovieLens.
OMDB is an open movie database, we now think of it as one of our services, and we can get the following information.
Movies
Classification of movies
The crew in the movie (director, action director, actors, post-production, etc.)
Movie covers, promos, etc.
MovieLens is an open dataset, we consider it as the user data of our services, the information we can obtain is:
Users
Movies
User interaction on movie ratings
Graph Modeling
We were building this Graph for a recommendation system and talked about some basic methods in this article, which:
In the Content-Base Filter method(CBF), the relationship of user-> movie, movie-> category, movie-> actor, and movie-> director are concerned.
And the collaborative filtering approach is concerned with the relationship for user-> movie.
The recommendation reasoning service is concerned with all the above relationships.
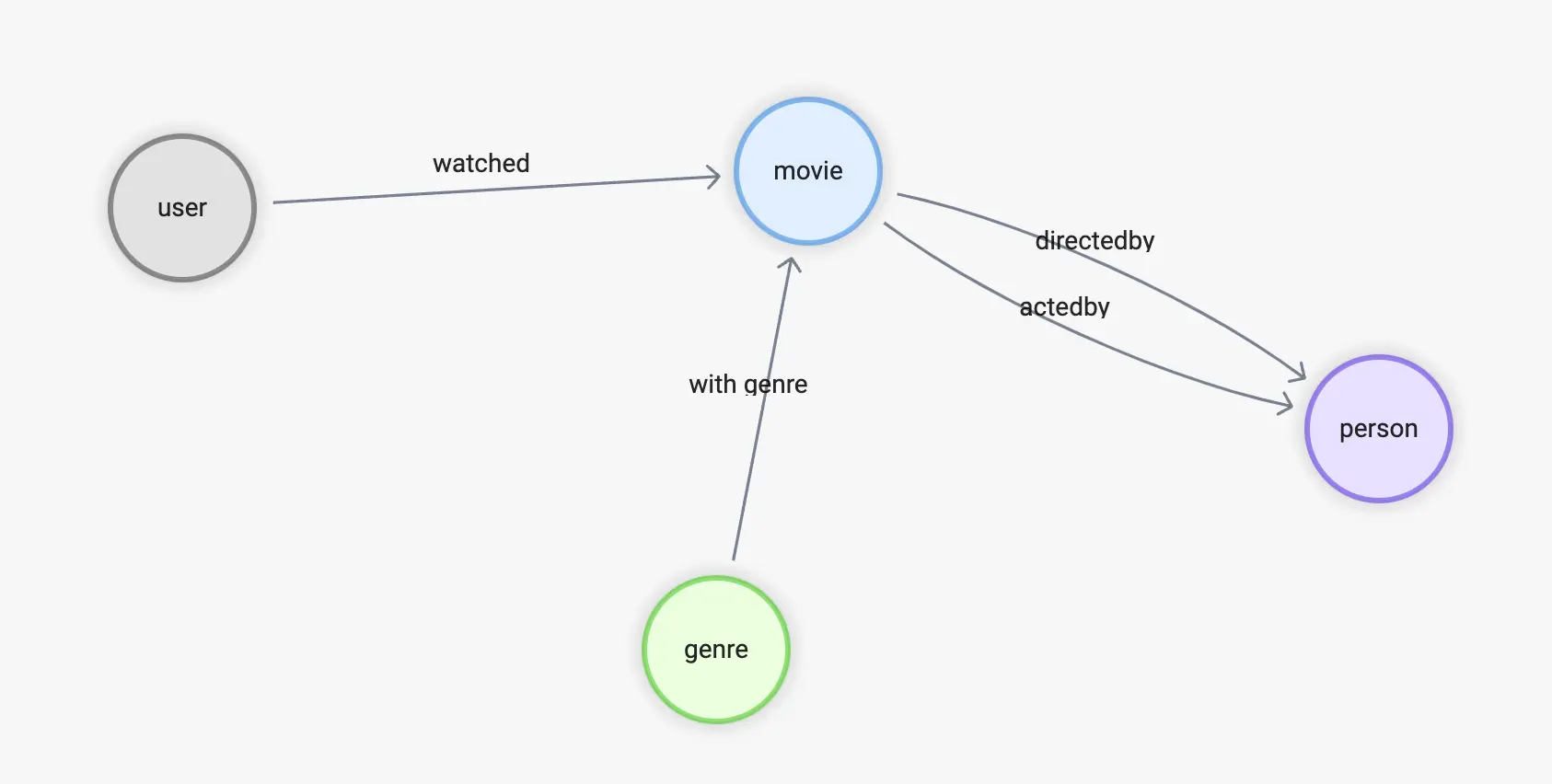
To summarize, we need the following edges:
watched(rate(double))
with_genre
directed_by
acted_by
Accordingly, for the vertex types will be:
user(user_id)
movie(name)
person(name, birthdate)
genre(name)
Data Transform
With the source date being finalized, let's see how they could be mapped and transformed into the graph from.
From OMDB
First, there is the data in OMDB, which consists of many tables, such as the table all_movies, which stores all the movies and their names in different languages.
movie_id | name | language_iso_639_1 | official_translation |
|---|---|---|---|
1 | Cowboy Bebop | de | 1 |
1 | Cowboy Bebop | en | 1 |
2 | Ariel - Abgebrannt in Helsinki | de | 0 |
3 | Shadows in Paradise | en | 0 |
3 | Im Schatten des Paradieses | de | 0 |
3 | Schatten im Paradies | de | 1 |
And the all_casts table holds all roles in the film industry.
movie_id | person_id | job_id | role | position |
|---|---|---|---|---|
11 | 1 | 21 | 1 | |
11 | 1 | 13 | 1 | |
11 | 2 | 15 | Luke Skywalker | 1 |
11 | 3 | 15 | Han Solo | 3 |
11 | 4 | 15 | Leia Organa | 2 |
But the name and other information of each person here, as well as the position he/she holds in the film, are in separate tables.
job_namesFor example, 1 stands for writer and 2 stands for producer. Interestingly, like movie id and name, job_id to name is a one-to-many relationship, because the data in OMDB is multilingual.
job_id | name | language_iso_639_1 |
|---|---|---|
1 | Autoren | de |
1 | Writing Department | en |
1 | Departamento de redacción | es |
1 | Département écriture | fr |
1 | Scenariusz | pl |
2 | Produzenten | de |
2 | Production Department | en |
all_people
id | name | birthday | deathday | gender |
|---|---|---|---|---|
1 | George Lucas | 1944-05-14 | \N | 0 |
2 | Mark Hamill | 1951-09-25 | \N | 0 |
3 | Harrison Ford | 1942-07-13 | \N | 0 |
4 | Carrie Fisher | 1956-10-21 | 2016-12-27 | 1 |
5 | Peter Cushing | 1913-05-26 | 1994-08-11 | 0 |
6 | Anthony Daniels | 1946-02-21 | \N | 0 |
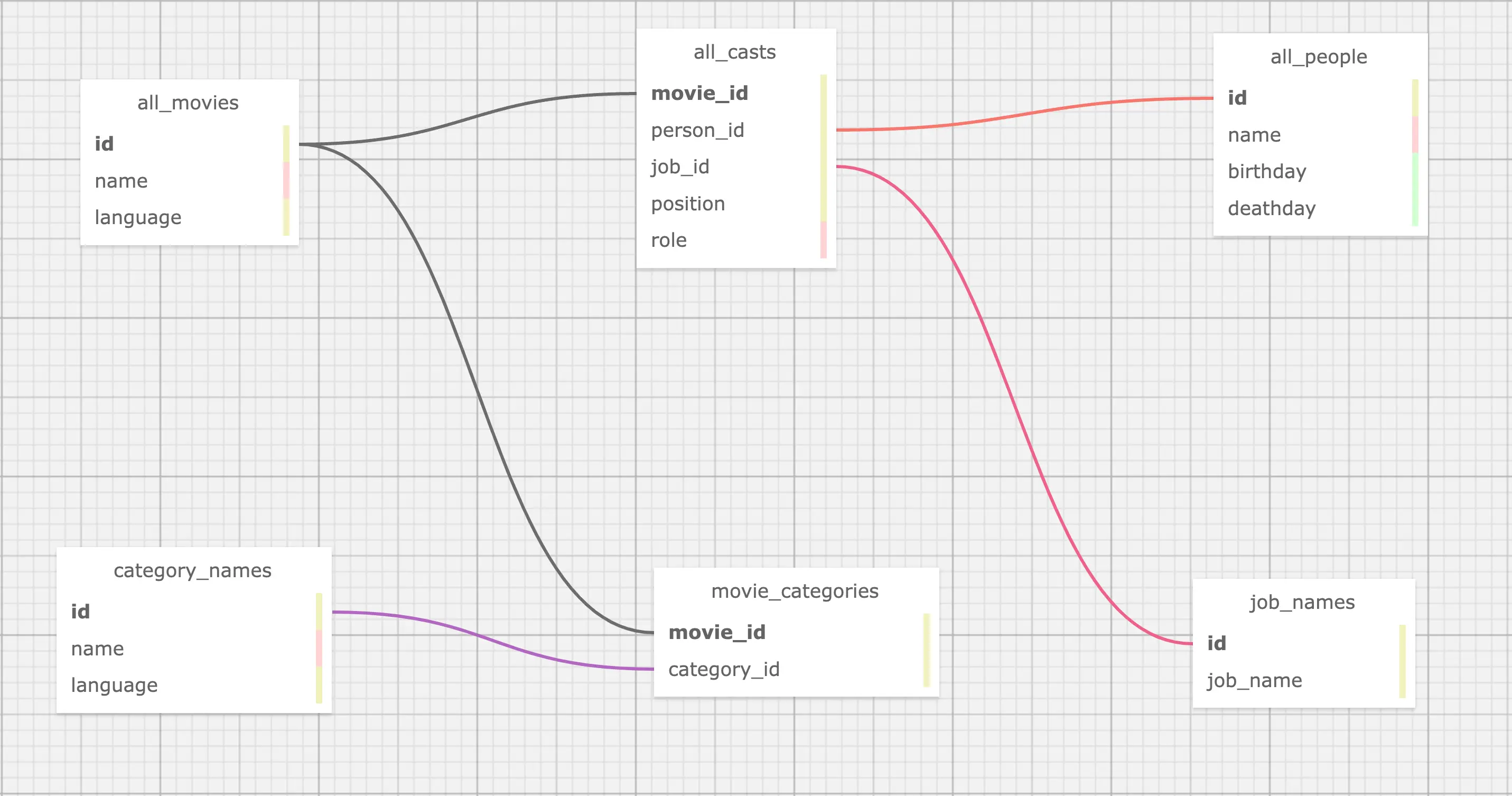
This is a typical case in RDBMS where the data source is a table structure, so for the relationship movie <-[directed_by]-(person), it involves four tables all_movies, all_casts, all_people, job_names:
directed_by
Starting from person_id in all_casts
To movie_id in all_casts
Where job_id is "director" in job_names
movie
person_id in all_casts
Name from all_movies by id, language is "en"
person
movie_id in all_casts
Name, birthday in all_people
Till now, all tables we cared in OMDB are:
From MovieLens dataset
While the above is just about one source of data, in real scenarios, we also need to collect data from other sources and aggregate them. For example, now also need to extract knowledge from the MovieLens dataset.
Here, the only relationship we utilize is: user -> movie.
movies.csv
movieId | title | genres |
|---|---|---|
1 | Toy Story (1995) | Adventure |
2 | Jumanji (1995) | Adventure |
3 | Grumpier Old Men (1995) | Comedy |
4 | Waiting to Exhale (1995) | Comedy |
ratings.csv
userId | movieId | rating | timestamp |
|---|---|---|---|
1 | 1 | 4 | 964982703 |
1 | 3 | 4 | 964981247 |
1 | 6 | 4 | 964982224 |
From the preview of the data in the two tables, naturally, we need one type of relationship: watched and vertex: user:
watched
Starting from the userId in
ratings.csvTo movieId in
ratings.csvWith rating from rating in
ratings.csv
user
With userId from
ratings.csv
However, you must have noticed that movieId in the MovieLens dataset and movie id in OMDB are two different systems, if we need to associate them, we need to convert movieId in MovieLens to movie id in OMDB, and the condition of association between them is movie title.
However, by observation, we know that:
the titles in OMDB movies are multilingual
the titles in MovieLens have the year information like
(1995)at the end of the title
So our final conclusion is
watched
Starting from the userId in
ratings.csvTo movieId in
ratings.csvGet the movie title with movieId from
movies.csvand find its movie_id from OMDBWhere we should match the title in language: English with the suffix of the year being removed
With rating from rating in
ratings.csv
user
With userId from
ratings.csv
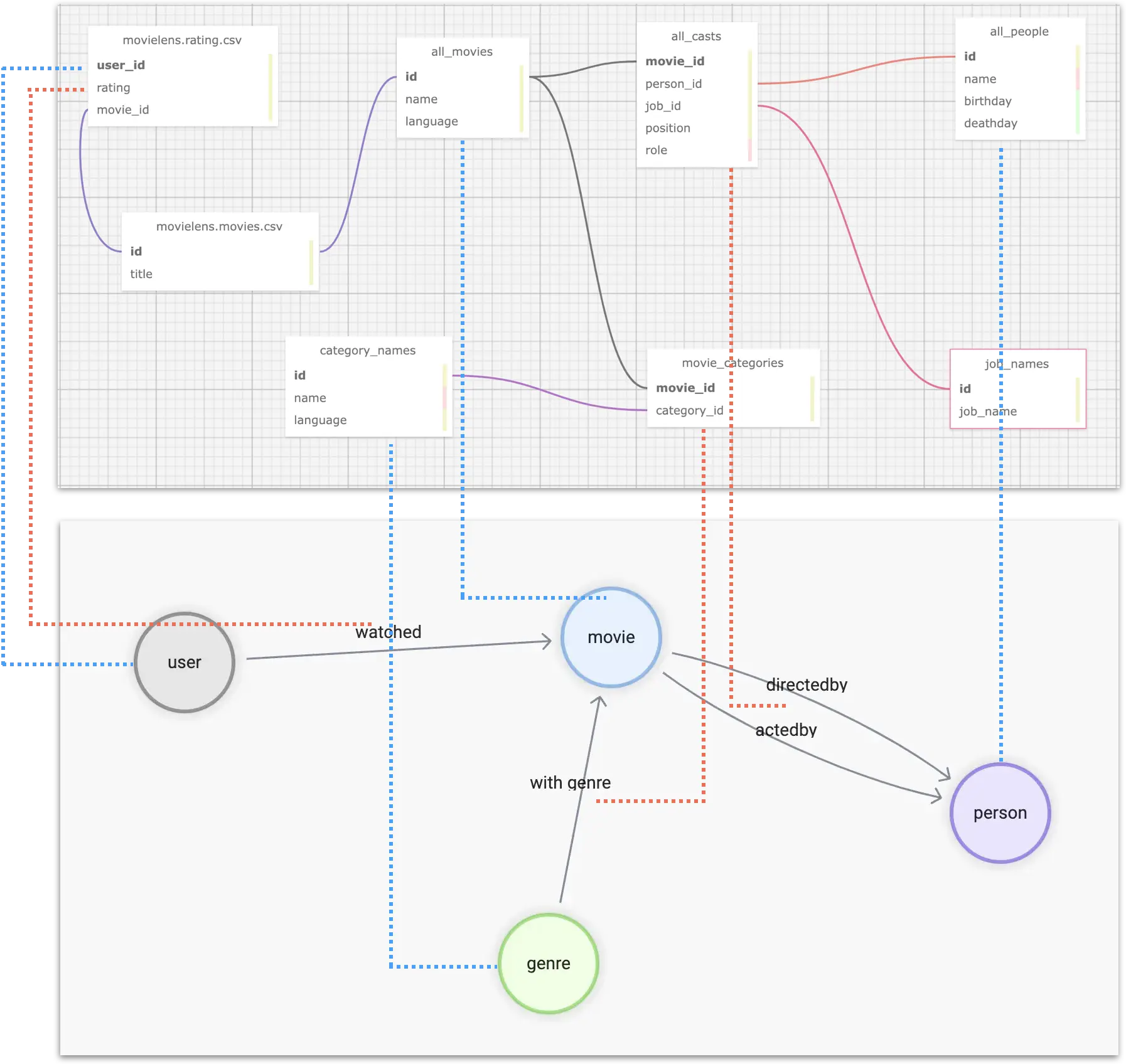
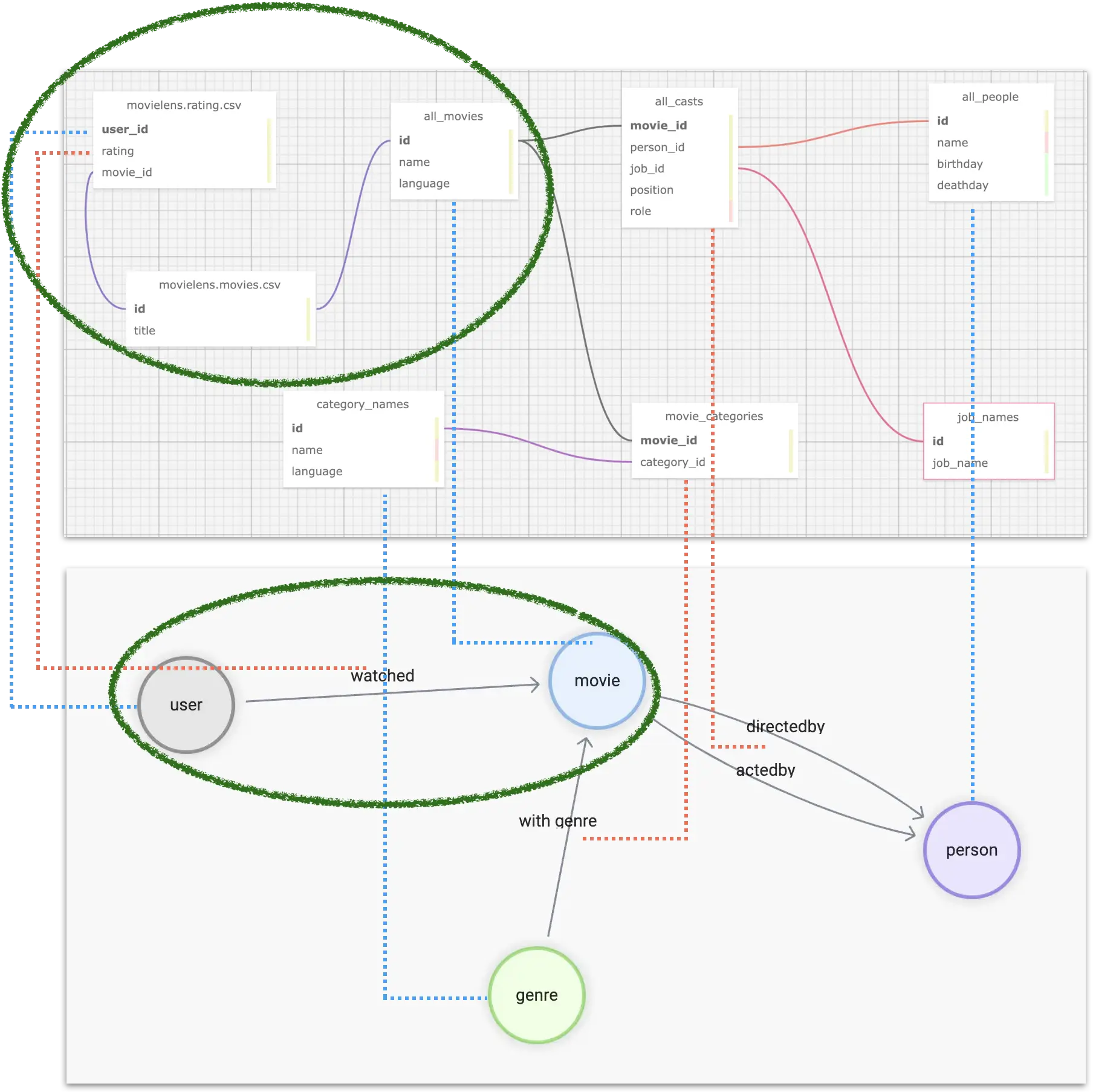
Now the modeling puts the two tables like this figure:
Graph Modeling (Property Graph)
To summarize, we need to aggregate different tables (or CSV files in table form) from multiple data sources, such that the correspondence is shown in the figure: where the blue dashed line indicates the source of data information for the vertices in the graph, and the pink dashed line indicates the source of edge information.
Then, we have to format the ids of individuals in different tables, for example, user_id, which is a self-incrementing number that we want to convert to a globally unique vertex_id. A convenient way to do this is to add a string prefix to the existing id, such as u_.
Eventually, for the relationship user -[watched]-> movie, we can process the table structure data as follows.
user_id | rating | title | omdb_movie_id |
|---|---|---|---|
u_1 | 5 | Seven (a.k.a. Se7en) | 807 |
u_1 | 5 | Star Wars: Episode IV - A New Hope | 11 |
u_1 | 5 | Star Wars: Episode IV - A New Hope | 10 |
u_1 | 4 | Mask, The | 832 |
u_1 | 3 | Mrs. Doubtfire | 832 |
Where, in each row, three variables exist to construct the graph structure:
uservertex idmovievertex idthe rating value of as the property of the
watchededge
Tooling
At this point, we have completed the data analysis and graph modeling design, before we start the "extract correlations, import graph database", let's introduce the tools we will use.
"Extracting relationships" can be simply considered as Extract and Transform in ETL, which is essentially the engineering of data mapping and transformation, and there are many different tools and open-source projects available on the market. Here we use one of my personal favorite tools: dbt.
dbt
dbt is an open-source data conversion tool with a very mature community and ecology, which can perform efficient, controlled, and high-quality data conversion work in most of the mainstream data warehouses, whether it is for ad-hoc tasks or complex orchestration, dbt can be very competent.
One of the features of dbt is that it uses a SQL-like language to describe the rules of data transformation. With GitOps, it is very elegant to collaborate and maintain complex data processing operations in large data teams. And the built-in data testing capabilities allow you to control the quality of your data and make it reproducible and controllable.
dbt not only has many integrated subprojects but also can be combined with many other excellent open source projects (meltano, AirFlow, Amundsen, Superset, etc.) to form a set of modern data infrastructure systems, feel free to check my previous article: data lineage and metadata governance reference architecture https://siwei.io/en/data-lineage-oss-ref-solution, where the whole solution looks like:

In short, dbt is a command line tool written in python, and we can create a project folder, which contains a YAML formatted configuration file, to specify where the source information for the data transformation is and where the target is (where the processed data is stored, maybe Postgres, Big Query, Spark, etc.). In the data source, we use the YAML file along with the .SQL file to describe the information about "what data to fetch from, how to do the transformation, and what to output".
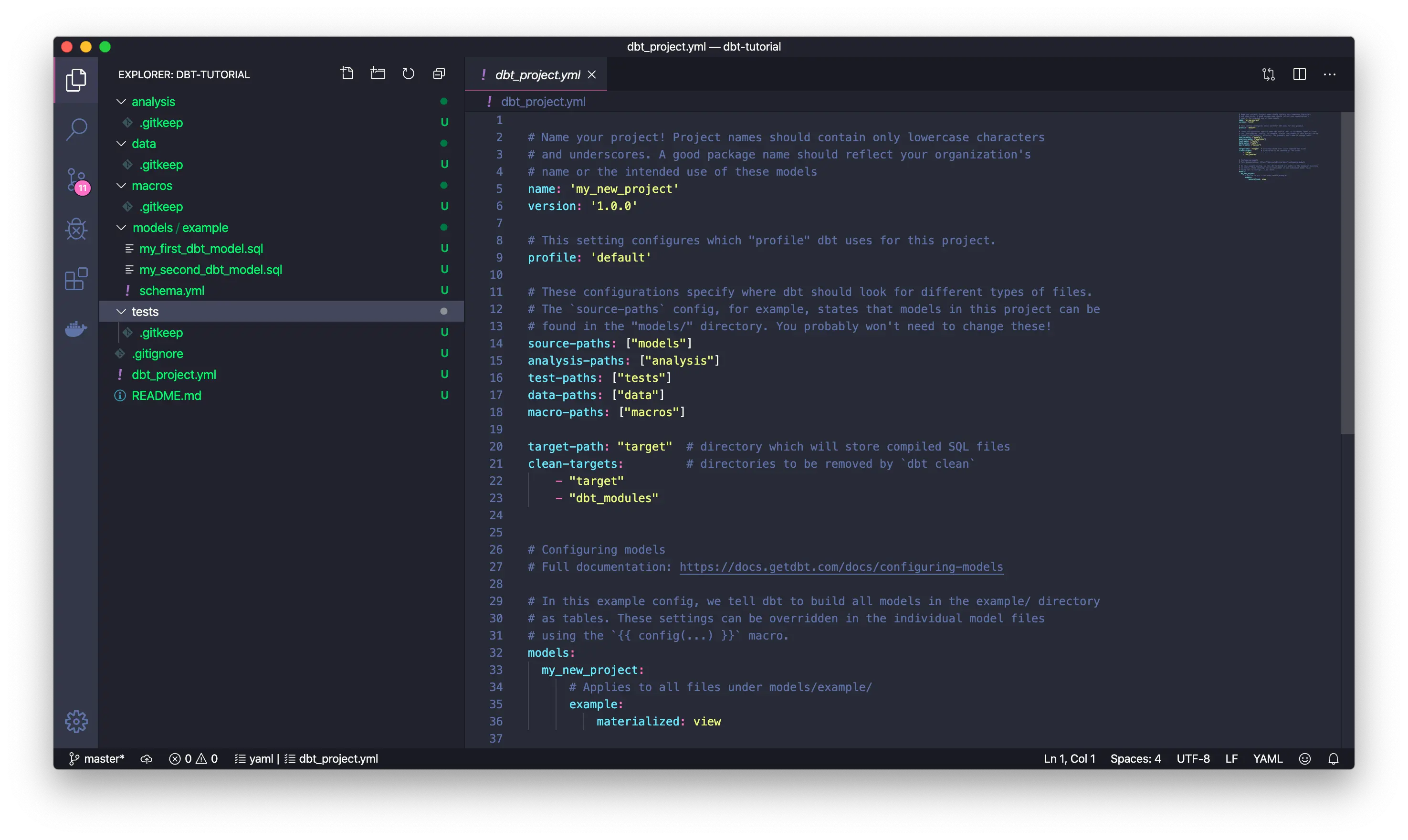
You can see that the information in the models/example is the core data transformation rules, and all the other data is metadata related to this transformation. DataOps.
Notes.
You can refer to the dbt documentation to get a hands-on understanding of it: https://docs.getdbt.com/docs/get-started/getting-started-dbt-core
NebulaGraph data ingestion
After processing the data by dbt, we can get intermediate data that maps directly to different types of vertices, edges, and table structures of their attributes, either in the form of CSV files, tables in DWs, or even data frames in Spark, and there are different options for importing them into NebulaGraph, of which NebulaGraph Exchange, Nebula-Importer, and Nebula-Spark-Connector can be used to import the data.
Notes.
You can learn more about the different tools for NebulaGraph data import at https://siwei.io/en/sketches/nebula-data-import-options to know how to choose one of them c.
Here, I will use the simplest one, Nebula-Importer, as an example.
Nebula-Importer is an open-source tool written in Golang that compiles into a single file binary, it gets the correspondence of vertices and edges from a given CSV file to a NebulaGraph for reading and importing via a preconfigured YAML format file.
Notes.
Nebula-Importer code: https://github.com/vesoft-inc/nebula-importer/
Nebula-Importer documentation: https://docs.nebula-graph.io/master/nebula-importer/use-importer/
dbt + Nebula-Importer in
Now let's use dbt + Nebula-Importer to end-to-end demonstrate how to extract, transform and import multiple data sources into NebulaGraph, the whole project code has been open-sourced, the repository is at https://github.com/wey-gu/movie-recommendation-dataset, feel free to check for details there.
The whole process is as follows.
Preprocess and import raw data into the data warehouse(EL)
Use dbt to transform the data (Transform), and export it to CSV files
Import CSV into NebulaGraph using Nebula Importer (L)
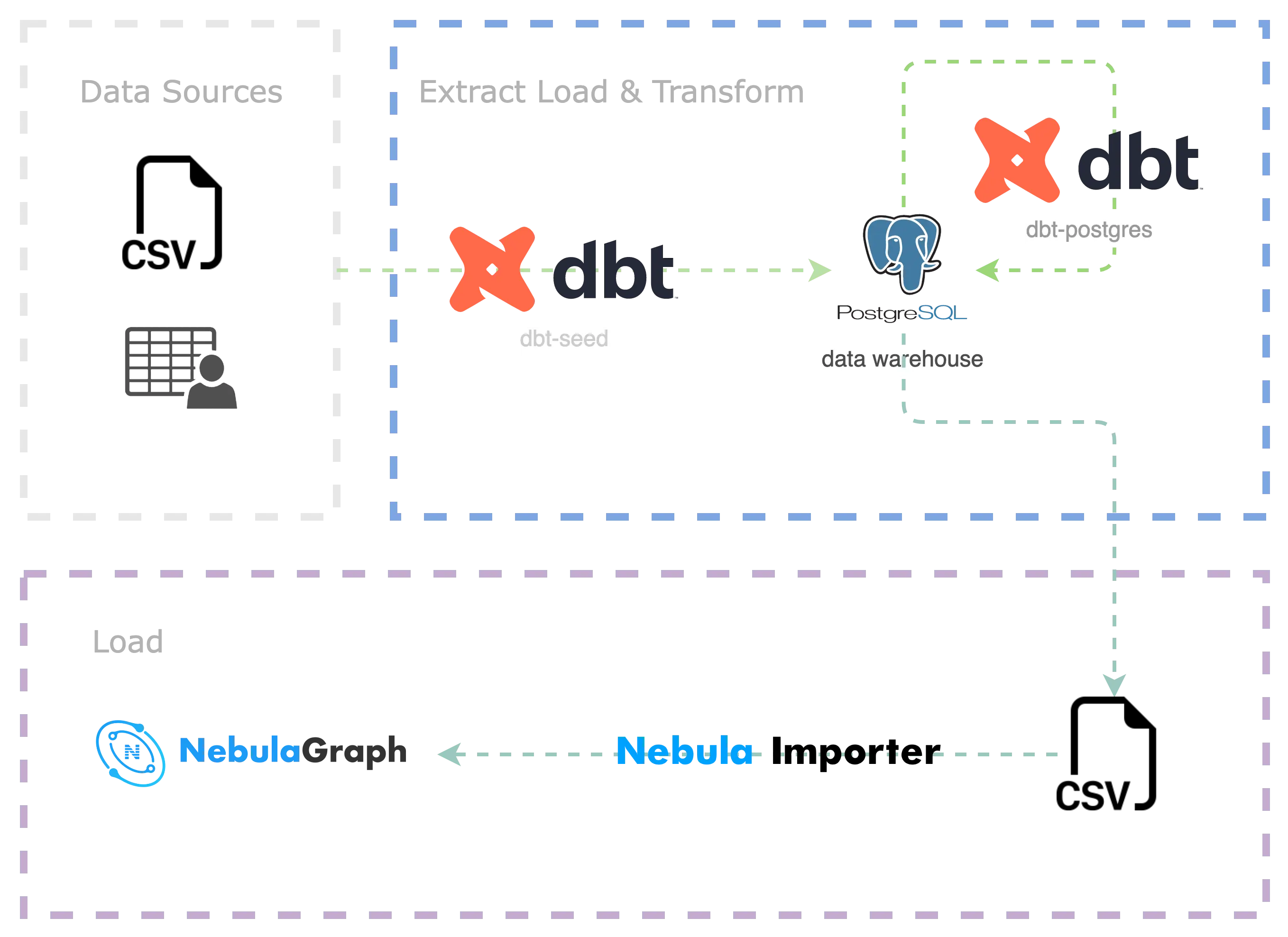
Preparing the dbt environment
dbt is a python project, we install dbt and dbt-postgres in a virtual python3 environment.
Setup env with dbt
dbt is written in python, we could install it in a python virtual env, together with dbt-postgres, as we will use Postgres as the DW in this sample project.
Create a dbt project:
Let's see the files in this project:
Finally, let's boostrap a Postgress as the DW, if you already have one, you may skip this step, please ensure the configurations and dbt-plugins are aligned if you chose to use your own DW.
Data download and preprocess
Let's create a folder named raw_data and change directory to it.
And we asummed it's under our dbt project:
Download and decompress the omdb data:
Then for then MovieLens dataset:
Before we do the Transform with dbt, we do some simple preprocess and then put them under seeds:
With above files being placed, we could load them into DW in one command:
Refer to the documentations of dbt
seedshttps://docs.getdbt.com/docs/build/seeds
It may take a while if you like me are using a local postgres, and it should be faster in produection level case(i.e. load to Big Query from file in Cloud Storage), it should be like this:
Compose the Transform model
We create transform under models:
The files are like:
Now there is only one transform rule under this model: to handle the edge of user_watched_movies in the user_watched_movies.sql
As we planned to ouput three columns: user_id, movie_id, rating, thus the schema.yml is like:
Please be noted the tests is about the validation and constraint of the data, with which, we could control the data quality quite easy. And here not_null ensures there is no NULL if tests are performed.
Then, let's compose the user_watched_movies.sql:
And what this SQL does is the part marked by the green circle:
Select user id, movie id, rating, movie title (remove the year part) from
moveielens_ratingsand save as the intermediate table ofuser_watched_moviesmovie title is
JOINed frommoveielens_movies, obtained by the same matching condition asmovie_id
Select user id (prefix
u_), rating, title, OMDB_movie_id fromuser_watched_moviesOMDB_movie_id is
JOINed fromall_movie_aliases_iso, obtained by matching the Chinese and English titles of OMDB movies by similar movie namesoutput the final fields
Tips: we could add
LIMITto debug the SQL query fast from a Postgres Console
Then we could run it from dbt to transform and test the rule:
After that, we should be able to see a table after the Transform in Postgres (DW).
Similarly, following the same method for all other parts of the Transform rules, we could have other models:
Then run them all:
Export data to CSV
In fact, NebulaGraph Exchange itself supports directly importing many data sources (Postgres, Clickhouse, MySQL, Hive, etc.) into NebulaGraph, but in this example, the amount of data we process is very small for NebulaGraph, so we just go with the most lightweight one: Nebula-Importer. Nebula-Importer can only CSV files, so we are doing so.
First, we enter the Postgres console and execute the COPY command
Refer to Postgres documentation: https://www.postgresql.org/docs/current/sql-copy.html
Then copy the CSV files into to_nebulagraph
Ingest data into NebulaGraph
Bootstrap a NebulaGraph cluster
We can use Nebula-Up to have a NebulaGraph playground cluster with the oneliner.
Note:
Nebula-UP: https://github.com/wey-gu/nebula-up
Dataset repository: https://github.com/wey-gu/movie-recommendation-dataset
Define the Data Schema
First, we need to create a graph space, and then create tag(type of vertex) and edge type on it:
Access the the Nebula-Console(CLI client for NebulaGraph):
Run the following DDL(Data Definiation Language):
Create a Nebula-Importer conf file
This conf is a YAML file that describes the correspondence between the CSV file and the vertex or edge data in the cluster.
Please refer to the document: https://docs.nebula-graph.io/master/nebula-importer/use-importer/ for details.
I already created one for it, which can be downloaded at https://github.com/wey-gu/movie-recommendation-dataset/blob/main/nebula-importer.yaml.
Here, we will directly download the configuration file.
Note that this file should not be part of the dbt project file.:
Ingesting the data
Let's use the Nebula-Importer in docker to avoid any installation:
After it's executed, all data are in NebulaGraph, and we could check the data from Nebula-Console:
First, access the console again:
Enter the graph space and execute SHOW STATS
The result should be like:
With Nebula-Studio, we can also explore this graph in the visual interface, for example, by executing this query, we could see the reason why it recommended the movie with id 1891 to the user with id u_124?
The result could be: Most of the cast and crew of the once-favorite Star Wars movies are also involved in this and the same "Oscar-winning" and "classic" movie.
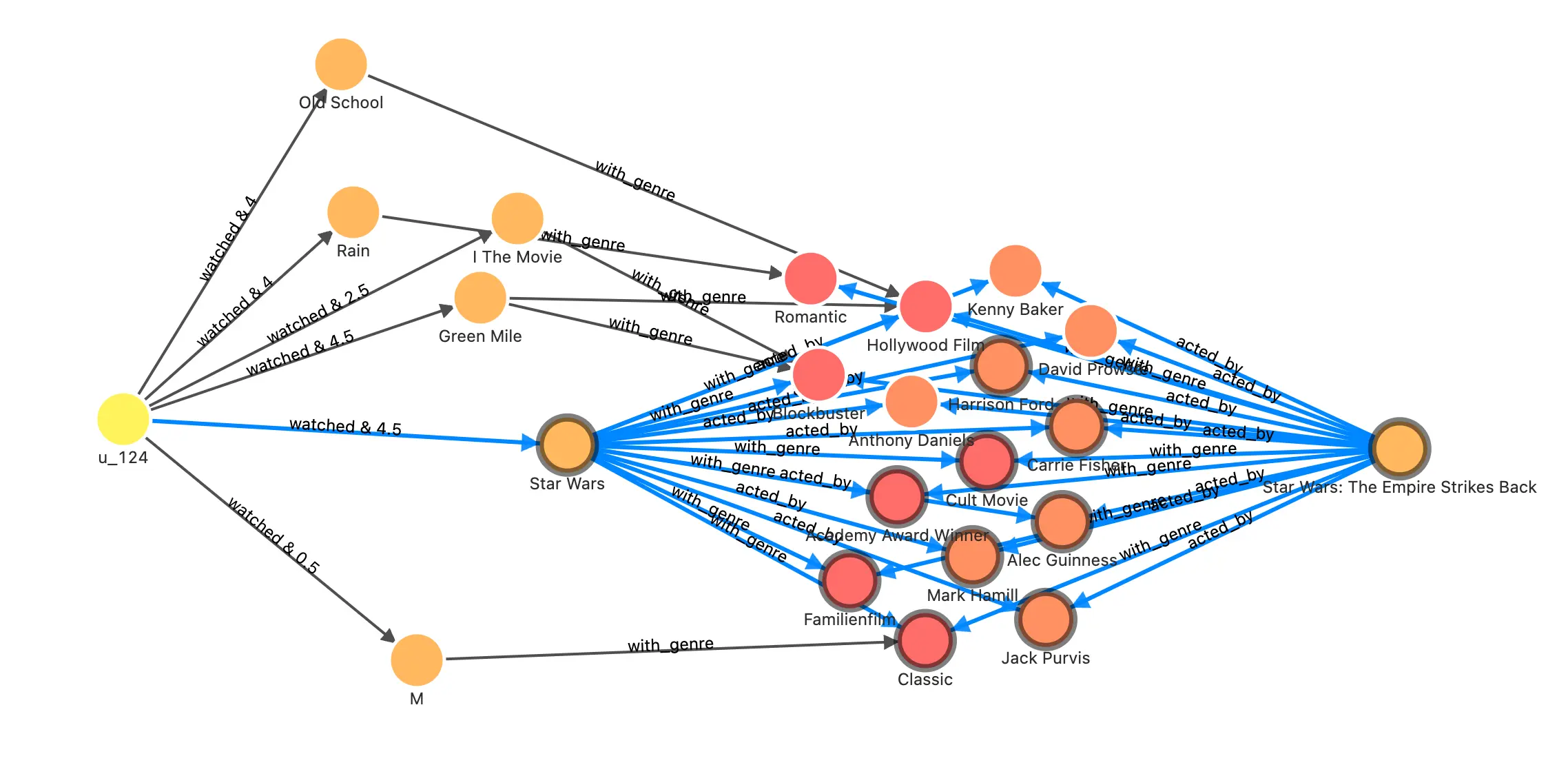
In another article, I used the same graph to demostrate the application of more graph databases and graph algorithms in recommendation systems. If you are interested, please read: https://siwei.io/recommendation-system-with-graphdb/.
Summary
When we plan to leverage graph databases for massive data to transform knowledge and analyze insights, the first step is often to transform, process, and model multiple data sources into graph data. For beginners who have no idea where to start, a feasible idea is to start from all relevant information, to picture the most concerned relationship, and then to list the vertices that can be obtained, as well as the required perpertices attached. After determining the initial modeling, you can use the ETL tool to clean the original data, ETL into table structure which will be mapped to the graph, and finally, use the import tool to import NebulaGraph for further model iterations.
With the help of dbt, we can version control, test, iterate our modeling and data transformation, and gradually evolve and enrich the constructed knowledge graph with grace.
Feature image credit: Claudio
