Community Spotlights
Jul 1, 2021
Validating Import Performance of Nebula Importer
duspring
Machine Specifications for Testing
Host Name | OS | CPU Architecture | CPU Cores | Memory | Disk |
|---|---|---|---|---|---|
hadoop 10 | CentOS 7.6 | x86_64 | 32 核 | 128 GB | 1.8 TB |
hadoop 11 | CentOS 7.6 | x86_64 | 32 核 | 64 GB | 1 TB |
hadoop 12 | CentOS 7.6 | x86_64 | 16 核 | 64 GB | 1 TB |
Environment of NebulaGraph Cluster
Operating System: CentOS 7.5 +
Necessary software for NebulaGraph Cluster, including gcc 7.1.0+, cmake 3.5.0, glibc 2.12+, and other necessary dependencies.
NebulaGraph version: V2.0.0
Back-end storage: Three nodes, RocksDB
Process \ Host Name | hadoop10 | hadoop11 | hadoop12 |
|---|---|---|---|
# of metad processes | 1 | 1 | 1 |
# of storaged processes | 1 | 1 | 1 |
# of graphd processes | 1 | 1 | 1 |
Preparing Data and Introducing Data Format
# of Vertices / File Size | # of Edges / File Size | # of Vertices and Edges / File Size |
|---|---|---|
74,314,635 /4.6 G | 139,951,301 /6.6 G | 214,265,936 /11.2 G |
More details about the data:
edge.csv: 139,951,301 records in total, 6.6 GB
vertex.csv: 74,314,635 records in total, 4.6 GB
214,265,936 vertices and edges in total, 11.2 GB

Validating Solution
Solution: Using Nebula Importer to import data in batch.
Edit a YAML file for importing data.
Create schema
On Nebula Console, create a graph space, and then tags and edge types in the graph space.
Compile
Compile Nebula Importer and run shell commands.
View the output
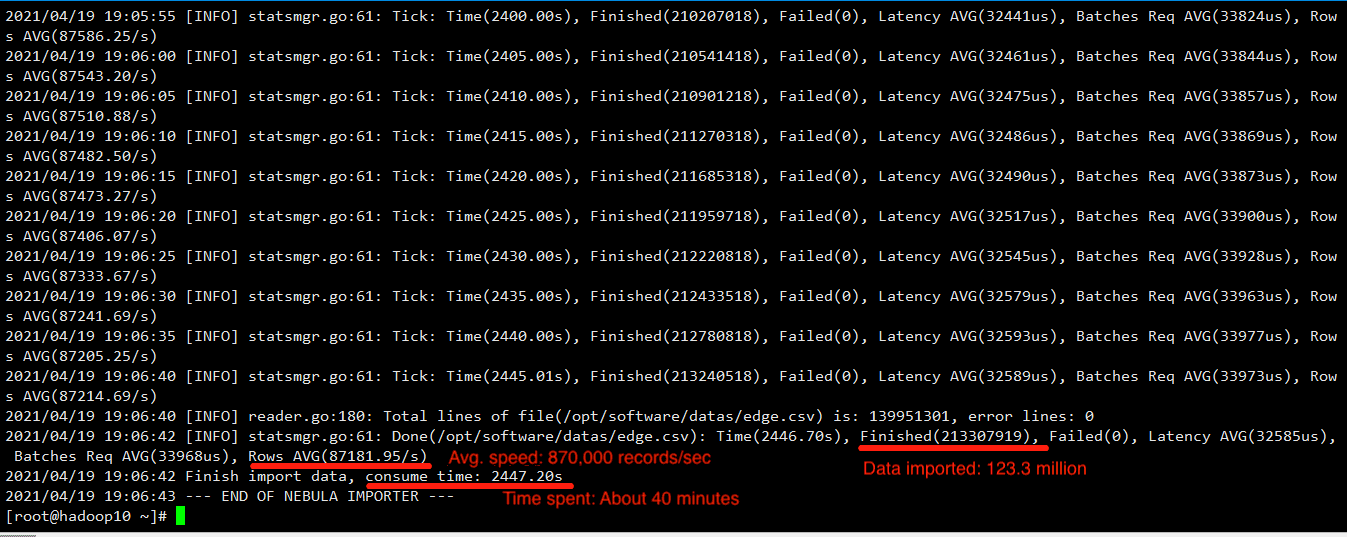
A special focus on the statistics of the statistics of results.
Resource Requirements
High requirement of the machine specifications, including the number of CPU cores, memory size, and disk size.
hadoop 10
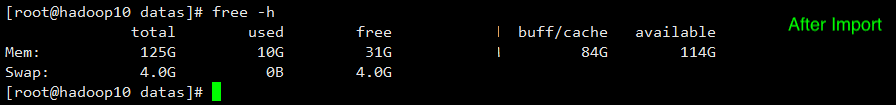
hadoop 11
hadoop 12
Recommendations on the machine specifications:
By comparing the memory consumption of the three machines, we found that the memory consumption is great when more than 200 million data are imported, so we recommend that the memory capacity should be as large as possible.
For the information about the CPU cores and disk size, see the documentation: https://docs.nebula-graph.io.
nGQL Statements Test
The native graph query language of NebulaGraph is nGQL. It is compatible with OpenCypher. For now, nGQL has not supported traversal of the total number of vertices and edges. For example, MATCH (v) RETURN v is not supported yet. Make sure that at least one index is available in a MATCH statement. If you want to create an index when related vertices, edges, or properties exist, rebuild the index after it is created to make it effective.
To test whether nGQL is compatible with OpenCypher.
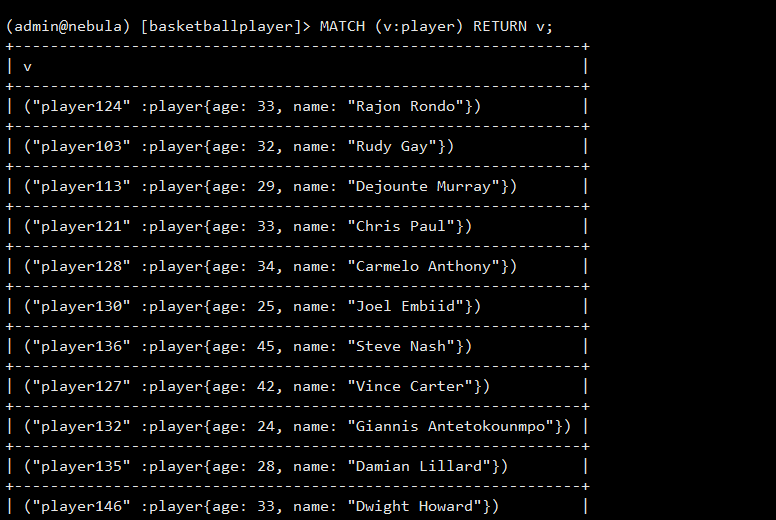
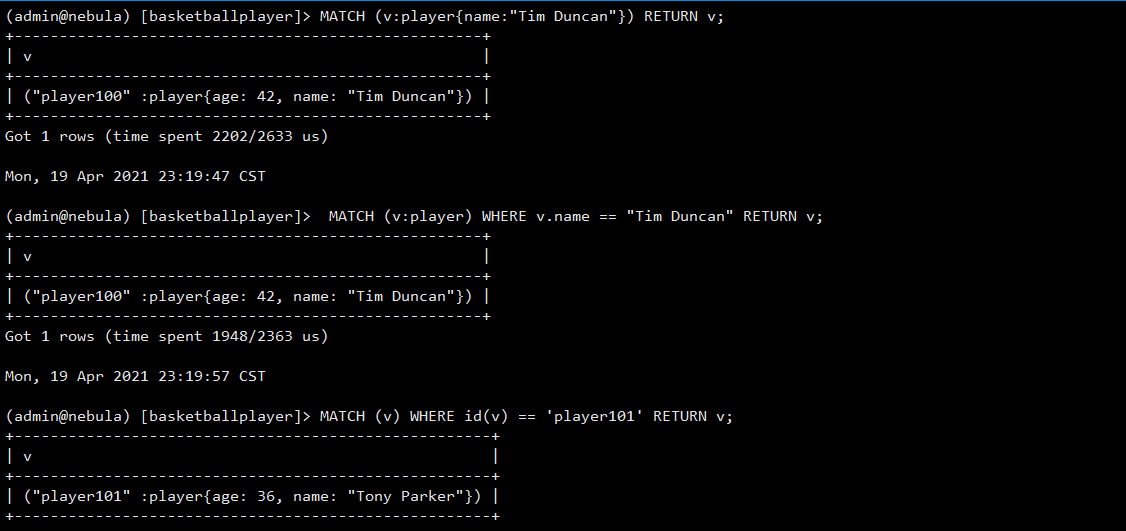
Conclusion
This test validated the performance of importing a large amount of data to a three-node NebulaGraph cluster. The batch writing performance of Nebula Importer can meet the performance requirements of the production scenario. However, if the data is imported as CSV files, it must be stored in HDFS and a YAML configuration file is needed to specify the configuration of the tags and edge types for processing by tools.
Would like to know more about NebulaGraph? Join the Slack channel!
