
Tech-talk
Technical Preview of NebulaGraph Enterprise v5.0
NebulaGraph Enterprise v5.0 is the latest offering of Vesoft, the first and now the only distributed graph database that implements the ISO/IEC 39075: GQL, the first international graph query language standard. As standardized by GQL and promoted by NebulaGraph in all previous versions, NebulaGraph Enterprise v5.0 adopts the property graph model for managing and storing user data mainly as vertices (nodes) or edges, each containing a set of labels and properties. Users get to use the market-proven MATCH (graph pattern matching) clauses in addition to a rich set of other SQL-like clauses to query such a property graph.
GQL
Similar to previous versions of NebulaGraph, the schema of a property graph is to be created or altered by users and managed by the database. The following code snippet is an example of a DDL query written in GQL that tries to create a graph type containing a set of node types (i.e., City, Country, Continent, etc.) and edge types (i.e., CITY_IS_PART_OF_COUNTRY, COUNTRY_IS_PART_OF_CONTINENT, etc.). Each node or edge type has its type name (e.g., City), a set of optional labels (e.g., City, Place) and a set of optional properties (e.g., id, name, url).
CREATE GRAPH TYPE IF NOT EXISTS ldbc_type AS {
NODE City (LABELS City&Place {id INT64 PRIMARY KEY, name STRING, url STRING}),
NODE Country (LABELS Country&Place {id INT64 PRIMARY KEY, name STRING, url STRING}),
NODE Continent (LABELS Continent&Place {id INT64 PRIMARY KEY, name STRING, url STRING}),
...
EDGE CITY_IS_PART_OF_COUNTRY (City)-[:IS_PART_OF]->(Country),
EDGE COUNTRY_IS_PART_OF_CONTINENT (Country)-[:IS_PART_OF]->(Continent),
EDGE UNIVERSITY_IS_LOCATED_IN_CITY (University)-[:IS_LOCATED_IN]->(City),
}
Once a graph type is created, we can use it to create as many graphs as we want, all of which would be confined to the same graph type. In the following, we create a graph with the name LDBC using the ldbc_type created above.
CREATE GRAPH IF NOT EXISTS LDBC TYPED ldbc_type
Assuming that we have loaded the LDBC graph with nodes and edges, we can query it using MATCH queries like the following that first declares two path patterns to be matched from the graph, order the results by the person.id and message.id properties, limit the cardinality of the result set to 20 and return a set of properties of interest.
MATCH
(person:Person)-[:KNOWS]->(friend:Person),
(message:Message)-[:HAS_CREATOR]->(friend)
ORDER BY
person.id DESC,
message.id ASC
LIMIT
20
RETURN
friend.id AS personId,
friend.firstName AS personFirstName,
friend.lastName AS personLastName,
message.id AS postOrCommentId
For a concise description of GQL, please refer to GQL Database Language published by ISO and Understanding GQL: A Comprehensive Overview of the Standard Graph Query Language.
Internals
Compared with the NebulaGraph v3.0 series, we have made fundamental technical advancements in all components of Enterprise v5.0. The following diagram compares the two architectures. The internals of the v3.0 and the Enterprise v5.0 are placed on the left- and right-hand side, respectively. For the Enterprise v5.0, the green boxes are new features in v5.0 and the red boxes are enhanced features over their counterparts in v3.0.
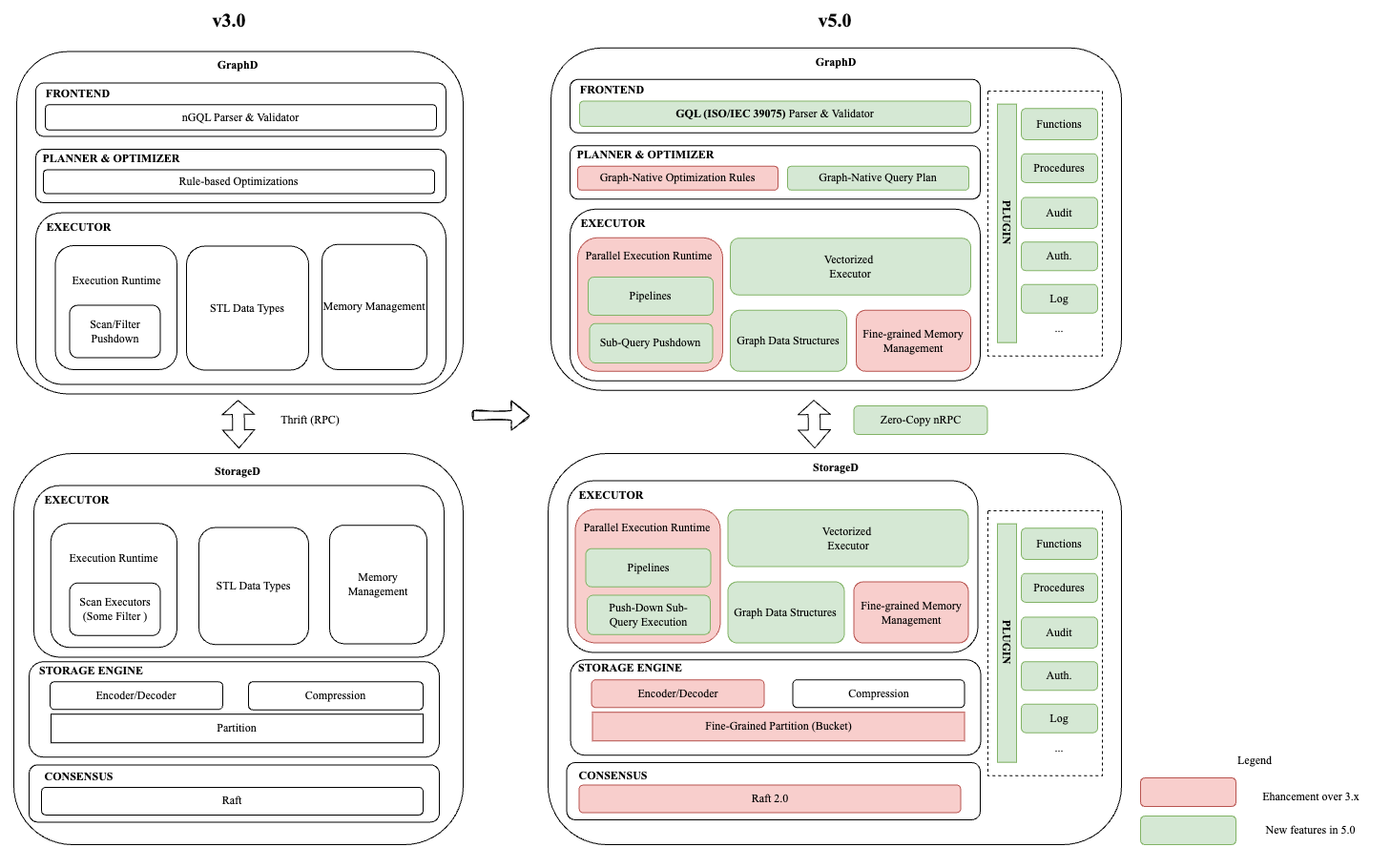
Full-Fledged Support for GQL
- New GQL frontend that parses and validates the GQL queries, conforming to the GQL standard.
- Deprecate previous vendor-locked query languages.
Distributed Architecture
- In the market, NebulaGraph has been known for its distributed architecture, the computing and storage capacity of which scales out nicely to cover even 200 TB of data of huge graphs in a single cluster. NebulaGraph Enterprise v5.0 honors the same architecture with major enhancement on the implementation of Raft, a consensus protocol for distributed systems.
- An Enterprise v5.0 cluster consists of a set of stateless graphd nodes and a set of storaged nodes organized in Raft groups. The metadata of each such cluster is managed by a metad service, consisting of metad nodes also organized in Raft groups. A single metad service can serve multiple clusters, if needed, in an isolated manner, all of which are referred to as a supercluster. This architecture is flexible and has been proven by the market to fit the needs of data management in enterprises.
Planner & Optimizer
- Enterprise-grade RBO (rule-based optimizations): The optimization of v5.0 has a rich set of optimization rules including both the market-tested ones inherited from the v3.0 series and new rules optimized for GQL. The Enterprise v5.0 does not start itself from ground zero but from the shoulder of the v3.0 series.
- Support graph-native operators that are specially designed and optimized for graphs in the query plans (e.g., breadth-first search in a graph) in addition to conventional relational algebra operators (e.g., joins).
Data Structures
- Compact Vectorized Layout: Within the memory, we store the data of graph elements (nodes and edges) in the newly designed Nebula Vector data structure that is compatible with Apache Arrow. Vector uses a compact layout to encode and store all data types such as strings, lists, records and so on, saving the memory overhead by up to 95% compared with the v3.0 series.
- No serialization/deserialization RPC overhead: The compact layout of vectors is RPC-friendly. The vectors are essentially a set of self-contained and sequentially stored data chunks in the main memory with no pointers. They can be passed via the RPC directly without any need to serialize or deserialize the data or allocating temporary memory spaces for this process.
- Memory Graph: We now support storing graphs using adjacency lists directly in the memory. This graph-native structure allows fast graph traversals and property retrievals by accessing the graph topology and properties directly in the memory, supporting queries that are orders of magnitude faster than those constrained by network & disk I/Os and KV encoding/decoding. We have exciting features based on this memory graph in future versions.
Executor
- Vectorized Executor: Instead of processing each row one by one, NebulaGraph Enterprise v5.0 now fully implements all operators in the vectorized way that applies operations on all values in a vector simultaneously. This allows the executor to exploit the hardware benefits of modern multi-core processors and DRAMs. As an example, the vectorized hash join operator is now 2-3 times faster than that in the v3.0 series.
- Fully concurrent and pipelined runtime: Instead of processing each operator one by one using only one thread, the Enterprise v5.0 now splits a query plan into multiple pipelines that are executed concurrently. Within each pipeline, data in the form of vectors streams from the first source operator to the final pipeline breaker without being blocked. And, at each point during the execution, there can be as many concurrent pipelines as needed and tuned. This runtime improves the workload balancing and exploitation of multi-cores significantly and addresses the NUMA problem in modern multi-socket multi-core processors.
- Sub-query plan pushdown: NebulaGraph Enterprise v5.0 can now push a complete sub-query plan from a graphd to multiple storaged for near-data processing (NDP). Previously, the v3.0 series benefited greatly from pushing some filters/predicates down to the storaged for performance improvements and network savings, despite that not all possible push-downs were implemented. We have greatly enhanced this feature from pushing down some filters/predicates to complete sub-query plans containing all possible operators, filters/predicates, etc. The push-downed sub-query plan is processed by the same pipelined and vectorized executors in the storaged.
- Fine-grained memory management: To prevent OOM failures, we have implemented a fine-grained memory tracker that can track the memory usage of each query, each operator as well as small objects in the runtime. In the same way as in the v3.0 series, users are free to set memory budgets and prevent the processes from being killed by OOM.
Storage Engine
- Optimized KV Encoding: We have optimized the KV encoding according to our latest understanding of how graph queries lookups, order and manipulate the underlying KV data. A new format is implemented to optimize prefix scans for nodes and edges.
- Bucket in partitions: Like in the v3.0 series, we continue to partition graph data in the shared-nothing architecture. In Enterprise v5.0, we split a partition into fixed-size buckets. All graph elements are mapped to corresponding buckets deterministically. The design allows faster data balancing and migration since data only needs to be moved at the bucket level. And, v5.0 supports altering the number of partitions after creating a graph.
Other Features
- Plugin: We now support plugins into the database kernel, as in popular databases like PostgreSQL. Quite some important features have been implemented as built-in plugins such as functions, procedures, authentications, etc. Developers can implement their own plugins in C++ and load them into the database kernel.
- Procedure: We support the development of procedures in C++. Users can call them in GQL queries. Procedures usually have better performance than plain queries. And, they can be reused once created. Users can also develop graph algorithms in procedures. We will support the development of GQL-based, Python-based procedures in future versions.
- For a complete feature list, please wait for our upcoming release note.
Performance
Now let’s look at how NebulaGraph Enterprise v5.0 performs in comparison with the latest enterprise version of the v3.0 series, v3.7. The following chart shows the speedup of v5.0 over v3.7 for the LDBC SNB Interactive benchmark, using the 99-th percentile of query latencies as the metric, on the same setup (a three-node cluster, 64-core Intel 8352Y CPU, 2.20GHz, 256 GB DRAM and 2 TB SSDs), with a scale factor (SF) of 100. Enterprise v5.0 is 1.01 to 6.43 times faster, with an average speedup of 3.01. All the queries executed on the v5.0 are written in GQL. For v3.7, the queries are written in openCypher. Both languages are based on the same graph pattern matching theory, with GQL released as the international standard. It has always been our belief that users shall only need to express their queries using declarative query languages and enjoy a good level of performance with ease, rather than being forced to write queries as procedures in C++. C++ procedures are good patches to the database. But it would be a nightmare if some queries could only be achieved with it because they are hard to code, hard to debug, hard to maintain and hard to scale.
Disclaimer: We used the LDBC SNB benchmark as a starting point. However, the test results aren’t audited, so we want to be clear that this is not an LDBC Benchmark test run, and these numbers are not LDBC Benchmark Results.
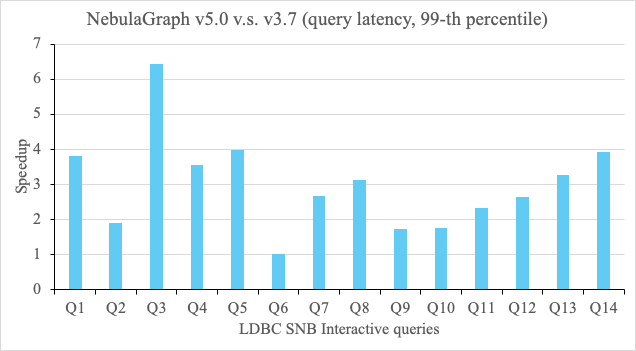
If we zoom in on the Q1 for example (GQL query shown in the following) on which v5.0 is 3.82 times faster, v5.0’s peak memory footprint of all processes is 64.47% smaller than that of v3.7. So, in a nutshell, Enterprise v5.0 can use around 1/3 of the memory resources to produce more than 3 times faster performance in this case.
USE ldbc
MATCH
(p:Person{id:2}),
(friend:Person{firstName:"Kyle"})
WHERE
p<>friend
MATCH
path1 = ANY SHORTEST PATH (p)-[:KNOWS]-{1,3}(friend)
RETURN
min(length(path1)) AS distance,
friend GROUP BY friend
NEXT
USE ldbc
ORDER BY
distance ASC,
friend.lastName ASC,
friend.id ASC
LIMIT
20
MATCH
(friend)-[:IS_LOCATED_IN]->(friendCity:City)
OPTIONAL MATCH
(friend)-[studyAt:STUDY_AT]->(uni:University)-[:IS_LOCATED_IN]->(uniCity:City)
RETURN
collect(CASE WHEN NOT uni.name IS NULL THEN RECORD
{uniName:uni.name,
studyAtClassYear:studyAt.classYear,
uniCityName:uniCity.name} END
) AS unis,
friend,
friendCity,
distance GROUP BY friend,
friendCity,
distance
NEXT
USE ldbc
OPTIONAL MATCH
(friend)-[workAt:WORK_AT]->(company:Company)-[:IS_LOCATED_IN]->(companyCountry:Country)
RETURN
collect(CASE WHEN NOT company.name is null THEN RECORD
{companyName:company.name,
workAtWorkFrom:workAt.workFrom,
companyCountryName:companyCountry.name} END
) AS companies,
friend,
unis,
friendCity,
distance GROUP BY friend,
unis,
friendCity,
distance
NEXT
USE ldbc
ORDER BY
distance ASC,
friend.lastName ASC,
friend.id ASC
LIMIT 20
RETURN
friend.id AS friendId,
friend.lastName AS friendLastName,
distance AS distanceFromPerson,
friend.birthday AS friendBirthday,
friend.creationDate AS friendCreationDate,
friend.gender AS friendGender,
friend.browserUsed AS friendBrowserUsed,
friend.locationIP AS friendLocationIp,
friend.email AS friendEmails,
friend.speaks AS friendLanguages,
friendCity.name AS friendCityName,
unis AS friendUniversities,
companies AS friendCompanies
Summary
ALL IN GQL: The upcoming NebulaGraph Enterprise v5.0 release is the first and now the only distributed GQL database. For the first time in the history of graph databases, we are thrilled to welcome the arrival of GQL. It not only allows users to develop applications in a standardized way without worrying about using vendor-locked languages but also enables us to develop a full-fledged graph database with both the latest database technologies and comprehensive grammar support for graph-native features.
Faster with Less Resources: Evaluated using the LDBC SNB benchmark, NebulaGraph v5.0 is on average 3 times faster and around 3 times more memory efficient than the previous state-of-the-art v3.7 enterprise version. We will release more evaluation results in more scenarios as the GA of Enterprise v5.0 approaches.
If you're interested in take a trial of NebulaGraph Enterprise v5.0, feel free to reach out to us.
About the author
Dr. Xuntao Cheng is the R&D leader of Vesoft and a member of the ISO/IEC JTC1/SC 32/WG3 Database Language expert group.



