Architecture
NebulaGraph Cloud on AWS:Auto Scale, Start Free
Summary
NebulaGraph is an open-source, distributed, and easily scalable native graph database capable of hosting very large datasets containing hundreds of billions of points and trillions of edges and providing millisecond queries.
Thanks to their unique data model and efficient query performance, graph databases play an important role in many business scenarios. Here are several typical business applications of graph databases:
- Knowledge Graph: Businesses and organizations need to build domain knowledge graphs from various data silos to support intelligent Q&A and semantic search.
- Social Network Analysis: Social network platforms need to analyze relationships, interests, and interactions between users to offer personalized recommendations and targeted advertisements.
- Financial Risk Control: Financial institutions need to monitor anomalous transaction activity, detect potential fraud, and assess credit risk.
- Recommendation system: E-commerce and media platforms need to provide personalized product or content recommendations based on the user's browsing history, purchase records, and other information.
NebulaGraph Cloud is a fully managed cloud service designed for NebulaGraph, and this article will detail how to realize cost reductions and efficiencies in synergy with AWS offerings.(For further instructions, please refer to the AWS Marketplace product landing page
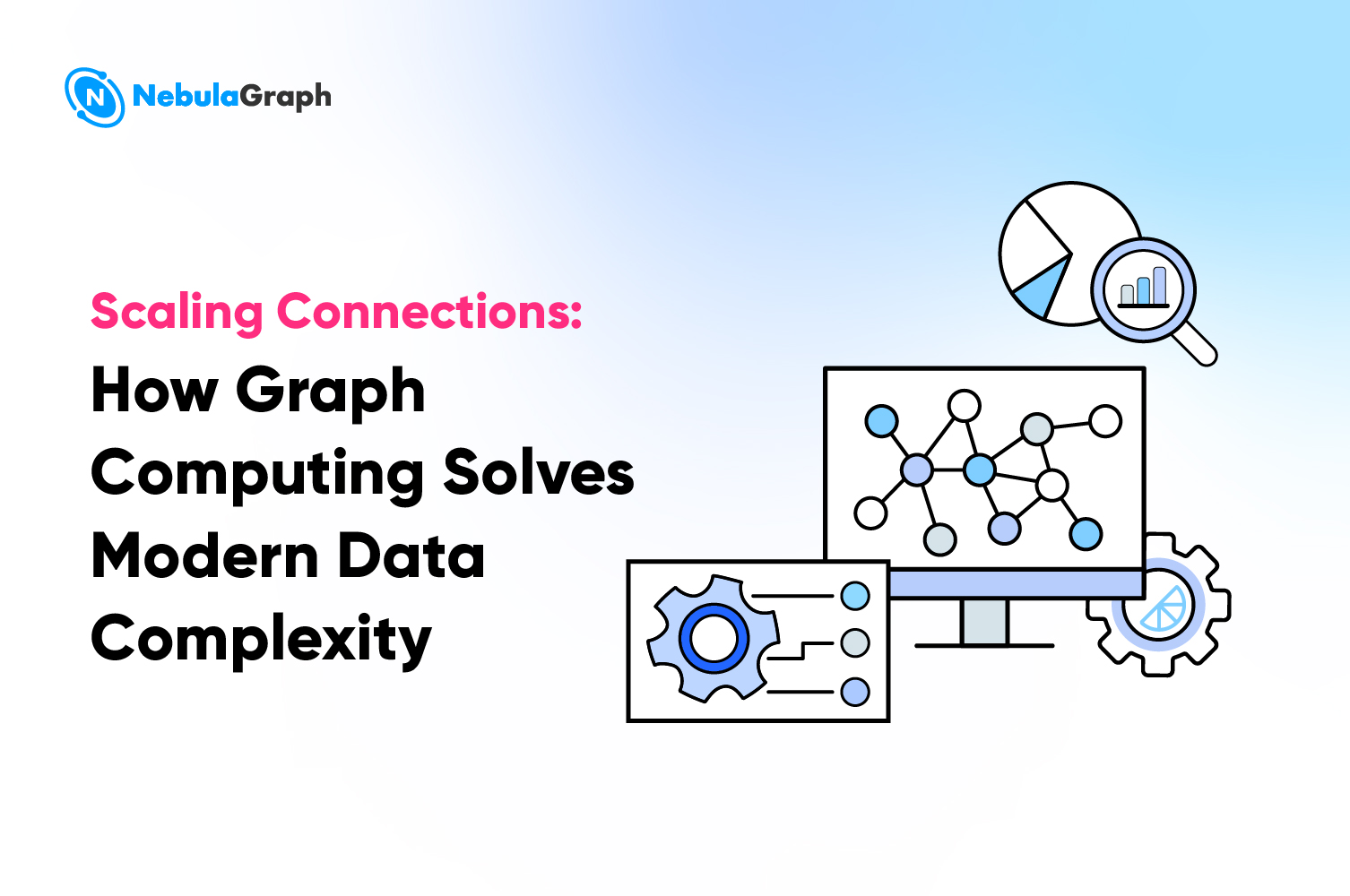
Platform architecture and components
Platform architecture
NebulaGraph Cloud is designed and built on K8S with the following considerations:
- K8S's Operator mode enables the automation of all internal cluster activities, significantly reducing development costs.
- K8S offers a range of abstraction capabilities to streamline the management of compute, storage, and network resources, which can help users avoid vendor lock-in and achieve complete cloud-agnostic
- K8S's inherent features such as scaling up and down, scheduling framework, resource monitoring, and service discovery simplify various management operations.
Service component
NebulaGraph Cloud is composed of two main parts:
Control Plane
The control plane provides user console access for organizational management, user rights control, database management, network security settings, monitoring, alerting, and various other features designed to assist users in managing their NebulaGraph clusters.
Data Plane
The data plane receives commands from the control plane, including resource scheduling, provisioning, versioning, horizontal scaling, specification adjustments, backup and recovery, observability, metering, and additional functions.
Cost-optimized design
Illustrated with a sample database configuration:
apiVersion: apps.nebula-cloud.io/v1alpha1
kind: Database
metadata:
name: db123456
namespace: db123456
spec:
provider: aws
region: "us-east-2"
k8sRef:
name: "k8s-ml65nmjg"
namespace: "k8s-ml65nmjg"
tier: standard
graphInstanceType: NG.C4.M32.D0
graphNodes: 1
StorageInstanceType: NG.C4.M32.D50
StorageNodes: 1
version: v3.8.2c
The database instance is defined using a Custom Resource Definition (CRD), and a database controller manages its operations within the control plane. Dependent compute resources are defined using the CRD NodePool, which is an abstraction of the compute resources of each cloud vendor, and is used to manage NodeGroups in AWS's EKS.As previously mentioned, NebulaGraph is a compute-storage separated architecture, so a database instance will correspond to two NodePool objects.
# Graph resource pool
apiVersion: apps.nebula-cloud.io/v1alpha1
kind: NodePool
metadata:
name: gnp-7d0b156e
namespace: db123456
spec:
databaseRef:
name: db123456
namespace: db123456
instanceCount: 1
instanceType: x
k8sRef:
name: k8s-ml65nmjg
namespace: k8s-ml65nmjg
labels:
platform.nebula-cloud.io/database-name: db123456
platform.nebula-cloud.io/graph-pool: db123456-f24a
provider: aws
region: us-east-2
zoneIndex: 0
# Storage resource pool
apiVersion: apps.nebula-cloud.io/v1alpha1
kind: NodePool
metadata:
name: snp-59e9cc63
namespace: db123456
spec:
databaseRef:
name: db123456
namespace: db123456
instanceCount: 1
instanceType: x
k8sRef:
name: k8s-ml65nmjg
namespace: k8s-ml65nmjg
labels:
platform.nebula-cloud.io/database-name: db123456
platform.nebula-cloud.io/Storage-pool: db123456-un6g
provider: aws
region: us-east-2
zoneIndex: 0
Specification adjustments
Choosing the appropriate instance size is a more challenging task than expected for both users and service providers. Users frequently struggle to determine the optimal instance size for their needs. For example, as a user's data grows from 100GB to 1TB, they may be uncertain about the required number of CPU cores or the amount of memory necessary at each stage. It is up to the user and the SA to collaborate and ascertain these requirements.
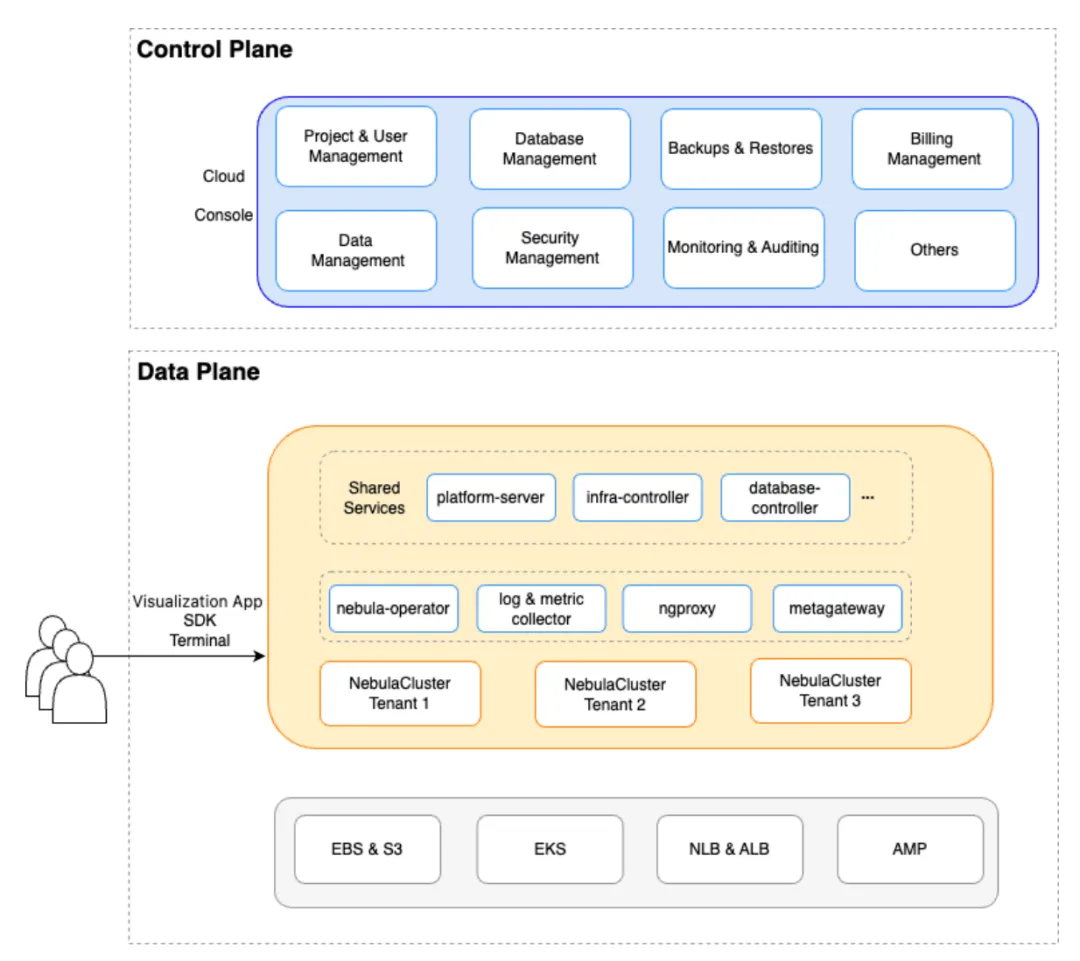
When using fully managed cloud services, we provide an instance specification tuning function, which supports individual tuning of Query nodes or Storage nodes to meet the needs of users in terms of cost control and performance standards. Users can determine whether a single-node processing bottleneck has been reached based on the historical curve of the monitoring panel, and the cloud platform will also issue an internal alert.
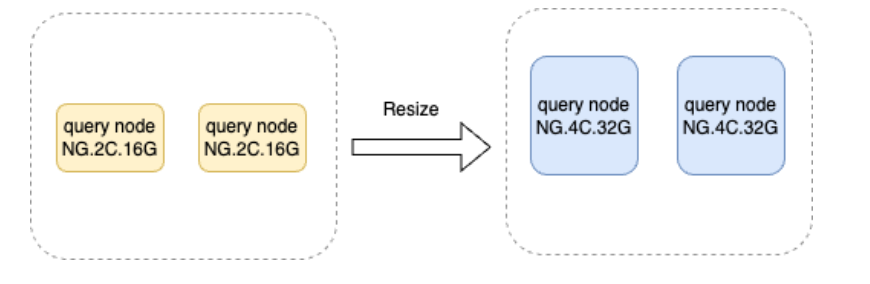
Horizontal expansion and contraction
Horizontal scale-up and scale-down supports individual tuning of the Query node, which can be regarded as a stateless service. This node can be scaled up or down to manage fluctuations in query traffic. Similarly, the Storage node, responsible for storing graph data and providing read and write capabilities, can also be scaled, with several data slices distributed across each Storage node. Each instance of expansion or contraction necessitates data migration and data slice rebalancing, thereby requiring meticulous operation.
Before proceeding with node expansion, it is essential to prepare the corresponding computing resources. The database controller will send the current desired number of nodes to the infra-controller to trigger the NodeGroup expansion of EKS. Here we do not enable CA or Karpenter for the following reasons:
- Scale-up/down decisions depend on specific cluster conditions and resource requests, and if these conditions are not met, it may not perform the intended scale-up/down operation
- Cross-availability scenarios do not guarantee the expansion and contraction of a given region
- The Pending Pod-based model is not tightly integrated with our business systems.
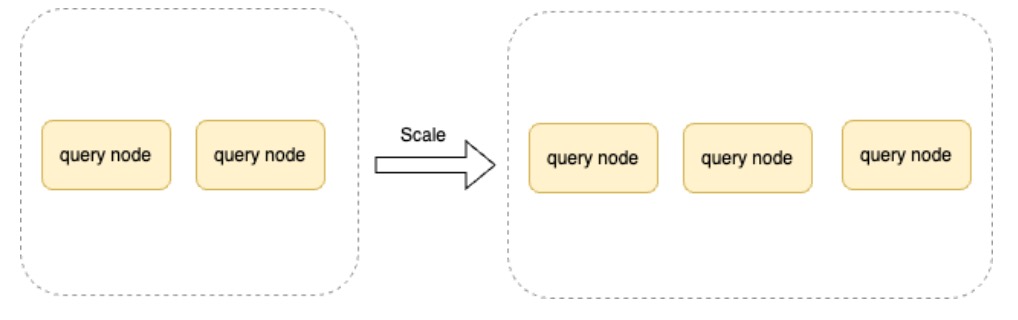
Automatic elastic expansion and contraction
Supporting different workloads through automatic scaling up/down is a critical goal for us. Since computing and storage are separated, we can increase or decrease CPU and memory resources based on the utilization of each service node.
The Elastic Scaling Service architecture is as follows:
Every 10 minutes, the Elastic Scaling Service calculates the amount of resources that should be allocated to a database instance based on historical and current values of the monitored data and ultimately determines whether compute resources should be increased or scaled down. It can drive both horizontal scaling and vertical scaling (adjusting instance specifications) to ensure that business peaks are popped ahead of time. We will continue to make continuous improvements on this foundation to shorten the time to scale up and scale down by incorporating more metrics and proactive prediction strategies.
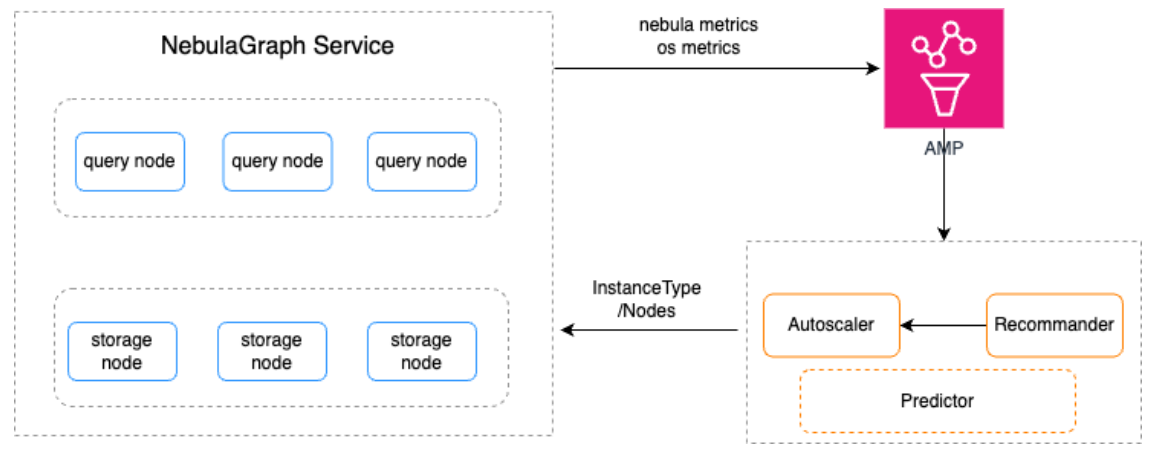
Design for Efficiency Improvement
Network security access
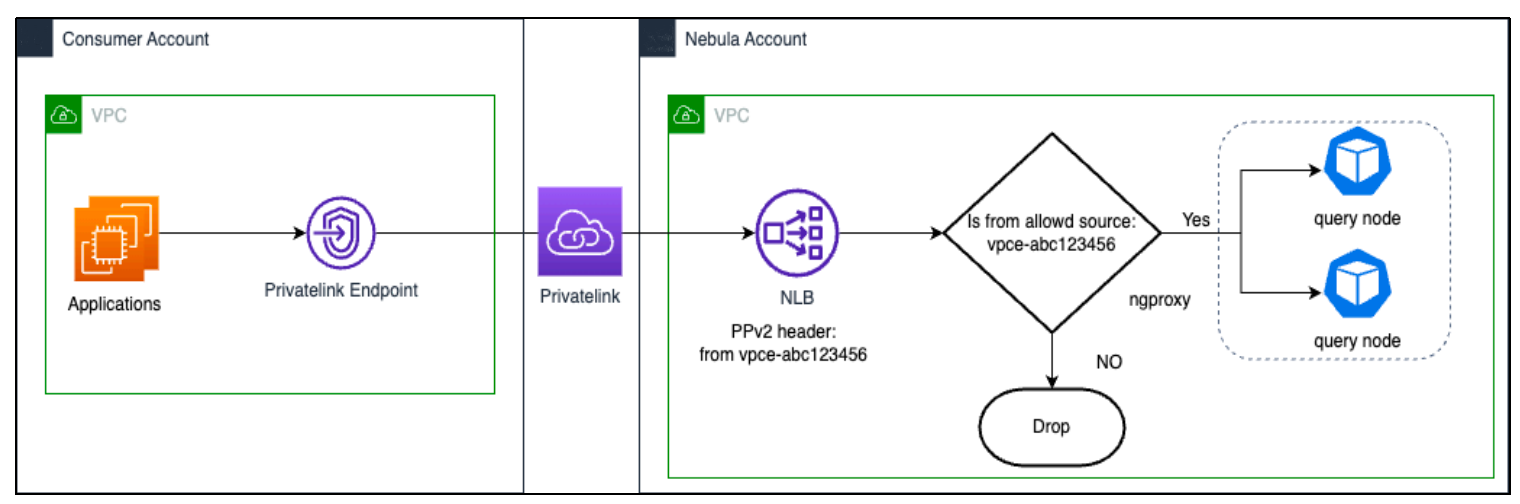
Currently, we offer two types of network connections to our users: network whitelisting and private link private connections. To ensure network security and simplify configuration steps, we introduced a proxy service, ngproxy, between the database instances and the Network Load Balancing (NLB), which takes full advantage of the functionality provided by the NLB.
The NLB is capable of setting a PPv2 header on every transmitted packet. ngproxy parses these packets to verify whether the user's endpoint ID matches the ID configured in the console, with any mismatched requests being rejected. The same principle applies to the public network. The same principle applies to the whitelisting of public network access. Only if the source address matches the address in the whitelist will it be allowed to pass.
Backup and recovery
Data backup serves as the primary defense against data loss, whether due to hardware failure, software error, data corruption, or human error, ensuring the safety of your data.
We provide users with both manual and scheduled backups and upload the backup data to AWS's object storage S3. We do not use a backup recovery solution based on cloud storage snapshots, as SST-based backup recovery is more rapid and does not depend on the cloud vendor's underlying services. Note that DDL and DML statements will be blocked during data backup, so it is recommended to perform backup operations during low business peak periods.
Backup data catalog structure:
backup_root_url/
- BACKUP_2024_08_20_16_31_43
├── BACKUP_2024_08_20_16_31_43.meta
├── data
│ └── 10.0.0.12:9779
│ └── data0
│ └── 5
│ ├── data
│ │ ├── 000009.sst
│ │ ├── 000011.sst
│ │ ├── 000013.sst
│ │ ├── CURRENT
│ │ ├── MANIFEST-000004
│ │ └── OPTIONS-000007
│ └── wal
│ ├── 1
│ │ ├── 0000000000000000001.wal
│ │ └── 0000000000000000005.wal
.....
│ ├── 30
│ │ ├── 0000000000000000001.wal
│ │ ├── 0000000000000000004.wal
│ │ └── 0000000000000000005.wal
└── meta
├── __disk_parts__.sst
├── __edges__.sst
├── __id__.sst
├── __indexes__.sst
├── __index__.sst
├── __last_update_time__.sst
├── __local_id__.sst
├── __parts__.sst
├── __roles__.sst
├── __spaces__.sst
└── __tags__.sst
- BACKUP_2024_08_20_19_02_35
Recovering data to a new instance of the program, so that you can take full advantage of the elastic expansion of resources on the cloud, specify a point in time after the backup set to quickly pull up a new database instance, and the user can be verified that the new database instance is working properly after the release of the old instance.
High availability
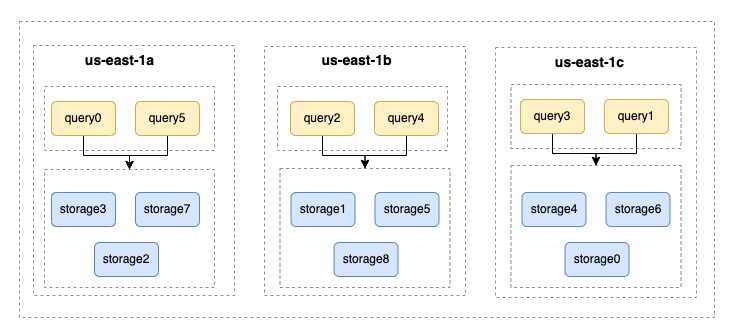
For those who demand the highest level of service reliability, we offer a cross-availability zone disaster recovery solution. In NebulaGraph, a zone is a collection of service nodes that divide multiple Storage nodes into manageable logical zones to achieve resource isolation. At the same time, the platform service controls the access of Query nodes to replica data within the designated Zone, thus reducing network latency and traffic costs incurred by cross-availability zone communication.
One of the main challenges in managing stateful services across availability zones is the issue of zone affinity of storage volumes. To address this issue, we have taken the approach of placing a NodeGroup in each availability zone. This avoids the possibility that a newly expanded Node may be incorrectly placed in an incorrect availability zone, resulting in the Pod not being scheduled.
Drawing from past user experiences, we also support the solution of expanding capacity individually in a certain availability zone. The cloud-native community's HPA-like solution only solves the problem of the quantity after expansion, but it cannot be expanded to a specified region. Scaling according to the business traffic carried by each region can effectively improve the quality of service. If a region observes a sudden surge in QPS, the elastic scaling service of the data plane will allow the scaling of Query nodes in this region.
Practical exercises on the cloud
Welcome to NebulaGraph Cloud . After initiating a subscription and creating a database, the next step demonstrates several ways to access the database:
Visualization tools
Select an instance from the Database list, go to Data->Graph graph space management, and click Explorer Graph to enter the visualization application.
Clicking on the Console in the upper right corner opens the console and allows you to execute queries for GQL statements.

network whitelisting
On the Overview page of the database instance, click Connect and select the Public method.
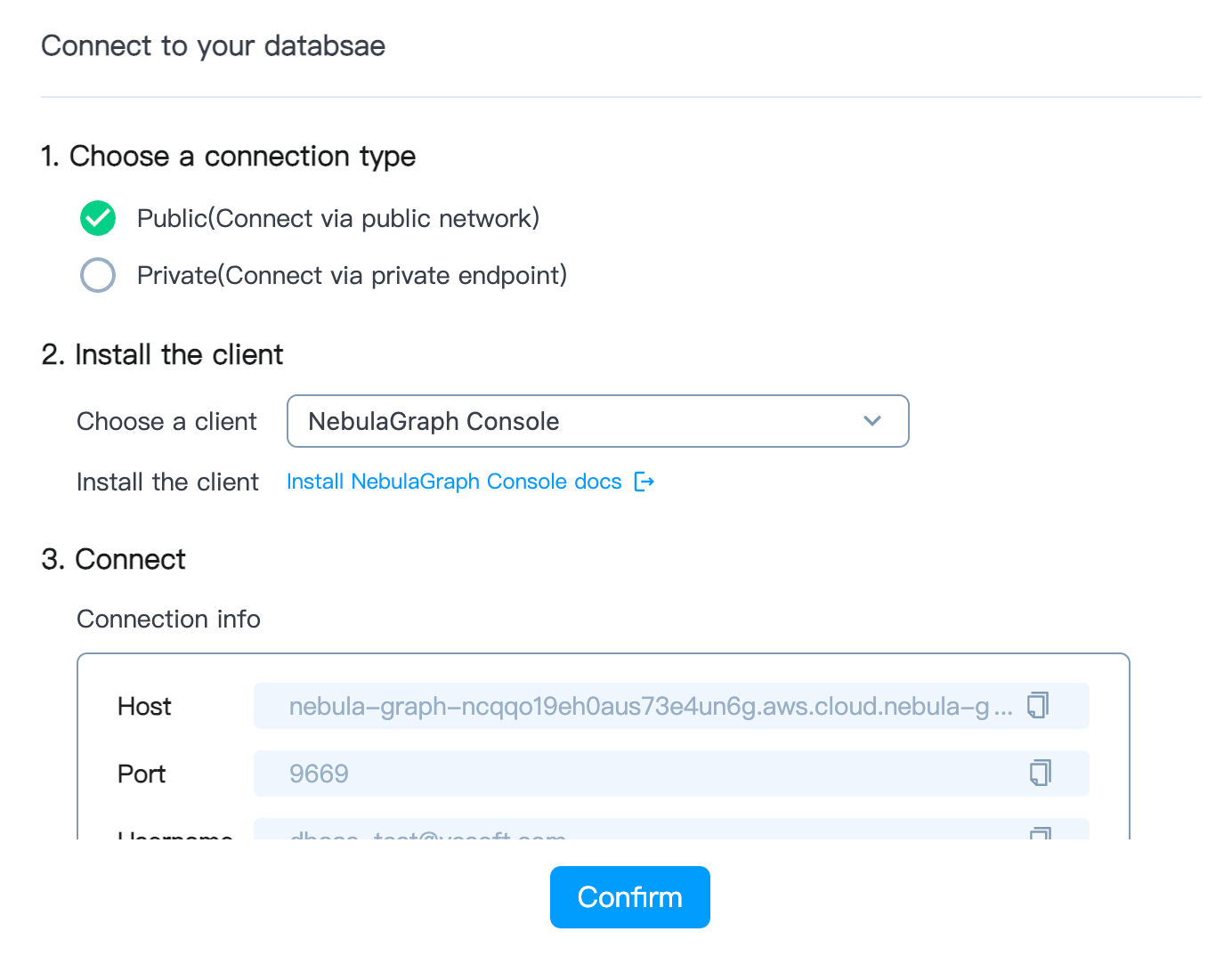 When network whitelisting is not configured, the database instance cannot be accessed directly from the public network.
When network whitelisting is not configured, the database instance cannot be accessed directly from the public network.
$ ./nebula-console -addr nebula-graph-ncqqo19eh0aus73e4un6g.aws.cloud.nebula-graph.io -port 9669 -u dbaas-test@vesoft.com -p $PASSWORD -enable_ssl
Welcome!
(dbaas-test@vesoft.com@nebula) [(none)]> show spaces;
+------------------------+
| Name |
+------------------------+
| "genshin" |
| "hanxiaotest" |
| "movie_recommendation" |
| "nba" |
+------------------------+
Got 4 rows (time spent 602µs/222.883326ms)
Mon, 02 Sep 2024 16:52:39 CST
Privatelink private network connection
Follow the configuration steps for Create Private Link Endpoint to determine the VPC ID and Subnet ID where the service resides.
Run the command to create the Endpoint:
aws ec2 create-vpc-endpoint --vpc-id <YOUR-VPC-ID> --region us-east-2 --service-name com.amazonaws.vpce.us-east-2.vpce-svc-04f25889c855f891b --vpc-endpoint-type Interface --subnet-ids <YOUR-SUBNET-IDs>
Log in to the AWS console to view Endpoint status

Test access within the business VPC
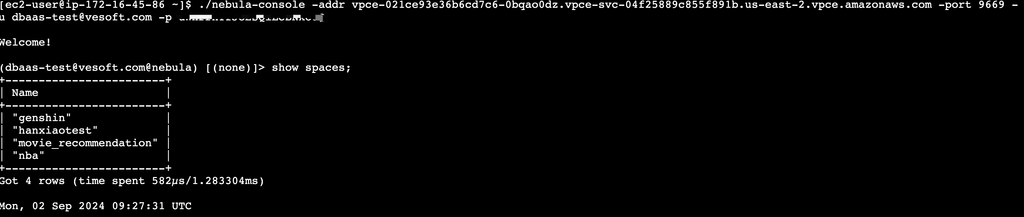 Next, you can maintain the data on the cloud through official eco-tools according to your business needs.
Next, you can maintain the data on the cloud through official eco-tools according to your business needs.
Summary and outlook
This paper describes the architectural details of landing a fully managed cloud service for NebulaGraph on AWS based on cloud-native concepts, focusing on how AWS offerings can yield substantial benefits to users, and provide a new solution that combines cost and elasticity advantages for using NebulaGraph in the cloud.
While ensuring the quality of our services, we will persist in exploring possibilities to reduce user costs and increase ease of use. Our goal is for users to pay only for the resources they use, implementing the concept of cost in every detail.
Beta trials are currently underway, with a maximum spend of $1 per month, and you can subscribe via AWS Marketplace or Sign up for an account.
If you are interested in NebulaGraph Cloud, please join the group to unlock more DBaaS-related content.