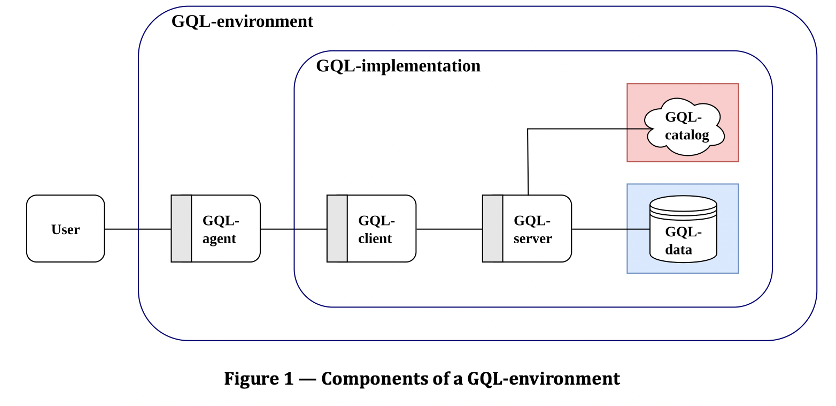
GQL
Beyond a Query Language: How GQL is Shaping the Future of Graph Databases
Since the recent release of the GQL (Graph Query Language) standard by ISO, there have been many discussions among graph database vendors and research institutions on how it will influence the industry. Apparently, its prevalence is backed by the wide applications of graph databases across diverse sectors- from recommendation engines to supply chains- a standard unified language for querying and managing graph databases is needed.
The significance of GQL lies in its ability to replace multiple database-specific query languages with a single, standardized one. This facilitates the interoperability between graph databases and calls the end of dependance of certain graph database vendors. Moreover, beyond the query language GQL defines, what a graph database should be and what key characteristics it should own are finally standardized, laying a far-reaching influential foundation to the development of the graph database industry. In this article, I will walk you through some important terms of GQL and explore its transformative potential for the industry.
Key Terms and Definitions of GQL
GQL aims to establish a unified, declarative graph database query language that is both compatible with modern data types and can intuitively express the complex logic of a graph. It defines a comprehensive and robust framework for interacting with property graph databases, including DQL, DML, DDL, providing a modern and flexible approach to graph data management and analysis. Below are some key definitions of GQL that developers or users of graph databases should be aware of.
Property Graph Data Model
GQL operates on a data model including nodes (vertices) and edges (relationships), which allows for pattern-based analysis and flexible data addition. The data model is specifically tailored for Property Graph Databases in that GQL is based on relatively mature graph query languages with wide applications, absorbing its advantages and settling the new standards.
Resource Description Framework (RDF), once another type of graph data model, is not included in GQL as a standard graph data model. With GQL definition, it is apparent that property graph data model is the de facto standard.
Graph Pattern Matching (GPM)
GPM language defined by GQL enables users to write simple queries for complex data analysis. While traditional graph database query languages support single pattern matching, GQL further facilitates complex pattern matching across multiple patterns. For example, GQL supports path aggregation, grouping variables and nested pattern matching with optional filtering, offering expressive capabilities to handle more sophisticated business logic.
GQL Schema
GQL allows for both schema-free graphs, which accept any data, and mandatory schema graphs, which are constrained by a predefined graph type specified in a “GQL-schema”. This dual approach of GQL supporting two types of schema caters to a wide range of data management needs, from the flexibility of schema-free graphs to the precision of schema-constrained ones.
Schema-free graphs allow adding new attributes to nodes or relationships at any time without modifying the data model. This adaptability is beneficial when dealing with complex and changing data, but from another perspective, schema-free graphs shifts the burden of data management complexities, such as handling data consistency and data quality, onto developers.
On the contrary, the mandatory schema graph offers a rigid framework that guarantees data consistency and integrity. The deterministic data structure within a mandatory schema makes any data changes clear and manageable. Furthermore, the predefined data structure enhances the comprehensibility and usability of data, which brings optimized query processes for both users and systems. While the mandatory schema graphs may sacrifice some flexibility, the trade-off is often justified in production environments where data structures are well-defined and the output data exhibits regular patterns.
Graph Types
Graph types are templates that restrict the contents of a graph to specific node and edge types, offering a certain level of data control and structure. Under GQL definition, a graph type can be applied to multiple graphs, which means that the same graph structure type can be shared in different applications, making it more flexible. For example, data of a business might differ in different departments, among various regions and the data permissions may be isolated from each other. Under this situation, using the same graph type can facilitate business management as multiple graphs with the same graph type enable permission management and data privacy compliance regulations.
Notable Advancements of GQL
Separation of GQL-catalog and GQL-data
GQL defines a persistent and extensible catalog initialization runtime environment with reference to SQL: GQL-catalog. GQL lists its stored data objects, including various metadata, such as graph, graph type, procedure, function, etc. GQL-catalog can be independently maintained or upgraded from data itself, which allows for flexible permission management and a unified, standardized approach to catalog management.
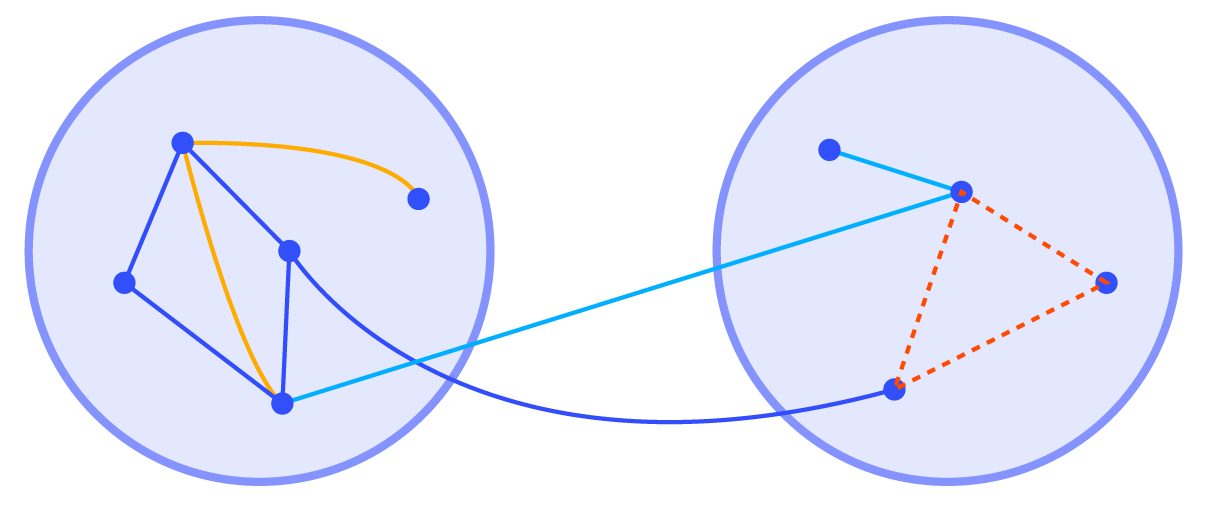
Multi-graph Joint Query
GQL enables multi-graph joint queries. By using different graph expressions in the query process, users can perform operations such as union, conditional rules, and join can be performed on different graphs. This capability benefits scenarios such as anti-fraud investigations and the integration of public and private knowledge graphs, where cross-referencing public and private data sets is crucial. These scenarios require both data isolation and integrated data analysis due to data compliance, maintenance and other reasons. Therefore, the data needs to be split into multiple graphs, but they need to be combined to complete a certain business requirement.
Supporting Undirected Graph
Different from the previous definition of graph databases where relationships always have a direction, GQL allows undirected graphs. In some scenarios, there is naturally no direction of relationships between vertices, such as friendships. While these relationships could be modeled as directed, doing so would necessitate two separate edges, making the modeling and querying process complicated.
Conclusion
In summary, the standardization of GQL is a significant step forward for the graph database industry. Not only providing simplified user experience, GQL regulates what property graph databases are and what features they should own, referring to real-world use cases. It boosts the transformative potential of graph databases for all industries where they are leveraged.
NebulaGraph Enterprise is the first distributed graph database to offer native GQL support in that it is built on GQL and designed for GQL. For those eager to experience the future of graph database querying, a free trial awaits. Reach out today to discover the power of GQL for yourself.