LLMs & AI
Aug 8, 2023
Graph + LLM|How NebulaGraph database helps industry-level large language model Applications
Wey
LLM App Paradigms
As a big improvement in Cognitive intelligence, LLM had changed many industries, in a way that we didn’t expect to automate, accelerate or enable. Seeing new LLM-enabled applications being created every day, we are all still exploring new methods and use cases for leveraging this magic.
One of the most typical patterns to bring LLM into the loop is to ask LLM to understand things based on proprietory/ certain domain knowledge. For now, there are two paradigms we could add that knowledge to LLM: fine-tuning and in-context learning.
Fine-tuning refers to performing add-on training on large language model models with extra knowledge, whereas in-context learning is to adding some extra piece of knowledge to the query prompt. What we observe now is that in-context learning has gained popularity over Fine-tuning due to its simplicity.
And in this blog, I’ll share what we had been doing around the in-context learning approach.
Llama Index: Interface between data and LLM
In-context learning
The basic idea of in-context learning is to use existing large language model(not updated) to handle special tasks toward specific knowledge datasets.
For instance, to build an application to answer any questions about one person, or even act as one’s digital avatar, we can apply in-context learning to an autobiography book with LLM. In practice, the application will construct a prompt with the question from the user and some information “searched” from the book, then query the LLM for an answer.
One of the most performant ways to enable this searching approach to get the related info from the Docs/Knowledge(the book in the above example) for the special task, is to leverage Embeddings.
Embedding
The LLM embedding normally refers to a way to map real word things into a vector in a multidimensional space, for instance, we could map images into a space of (64 x 64) dimension, and if we are doing it well enough, the distance between the two images can reflect the similarity of them.
Another example of embedding is the word2vec algorithm, which literally maps every word into a vector, for instance, and if the embedding is good enough, we could have addition and subtraction on them, we may have:
vec(apple) + vec(pie) =~ vec("apple apie")Or the vector measure ofvec(apple) + vec(pie) - vec("apple apie")tends to be 0: *|vec(apple) + vec(pie) - vec("apple apie")| =~ 0Similarly, we could have “pear” should be closer than “dinosaur” to “apple”:|vec(apple) - vec(pear)| < |vec(apple) - vec(dinosaur)|With that, we could in theory search for pieces of the book which are more related to a given question. And the basic process is:Split the book into small pieces, create the embedding per each piece, and store them
When a question comes, compute the embedding of the question Find top-K similar embeddings of pieces of the book by calculating the distance
Construct the prompt with both the question and the pieces of the book
Query the LLM with the prompt
Llama Index
Llama Index is such an open-source toolkit to help in-context learning in best practice:
It comes with a bunch of data loaders to serialize docs/knowledge in a unified format, think of PDF, Wikipedia Page, notion, Twitter, etc, and we don’t have to deal with the preprocessing, split the data into pieces, etc, on our own.
It helps create the Embedding(and some other form of the index) for us and stores the embeddings(in memory or vector databases), too, with one line of code.
It comes out of the box with prompts and other engineering points, so that we don’t have to create and study from scratch, for instance, create a chatbot on existing data with 4 lines of code.
The problem of doc split and embeddings
The embedding and vector search worked well in many cases, while there are still challenges in some cases, and one of them is it could lose global context/cross-node context.
Think of we are asking “Please tell me things about the author and foo.”, and in this book, the piece with numbers: 1, 3, 6, 19~25, 30~44, and 96~99 are all about the topic of foo. In this case, the simple way of searching top-k embedding of the pieces of the book may not work well because we normally only take a few top-related pieces, which loses many contexts.
The mitigation for that, for instance with Llama Index is to create composite indices, where the VectorStore is only part of it, combining with that, we could define a summary index and/or a tree index, etc to route different types of questions to different indices, thus to avoid risking the loss of global context when the question required it.
Or, with the help of Knowledge Graph, we could do something differently.
Knowledge Graph
The term Knowledge Graph was initially coined by Google in May 2012 as part of its efforts to enhance search results and provide more contextual information to users. The Knowledge Graph was designed to understand the relationships between entities and provide direct answers to queries rather than just returning a list of relevant web pages.
A knowledge graph is a way of organizing and connecting information in a graph format, where nodes represent entities, and edges represent the relationships between those entities. The graph structure allows for efficient storage, retrieval, and analysis of data.
It looks like this:
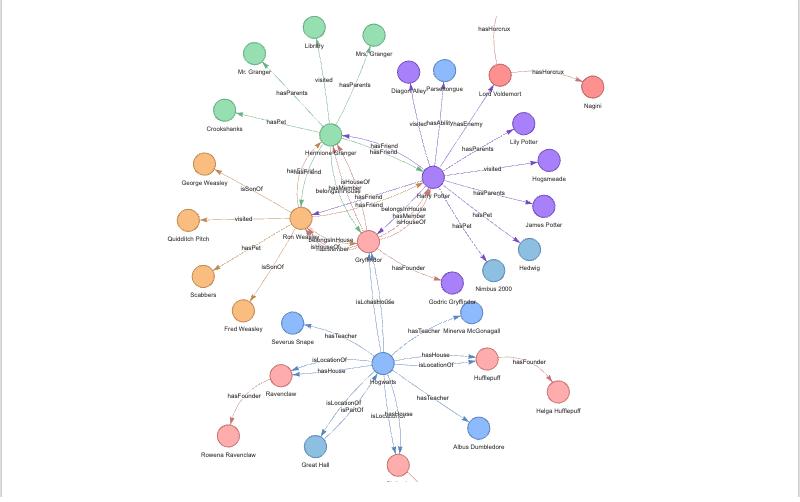
But how could Knowledge Graph help?
Combination of LLM embeddings and Knowledge Graph
The general idea here is a knowledge graph, as the refined format of the information, can be queried/searched in way smaller granularity than the split we could do on raw data/docs. Thus, by not replacing the large pieces of the data, but combining the two, we can search queries that require global/cross-node context better.
See the following diagram, assume the question is about x, and 20 of all the pieces of the data are highly related to it. We could now still get the top 3 pieces of the doc(say, no. 1, 2, and 96) as the main context to be sent, apart from that, we ask for two hops of graph traversal around x from the knowledge graph, then the full context will be:
The question “Tell me things about the author and
xRaw doc from piece number 1, 2, and 96, in Llama Index, it’s called node 1, node 2, and node 96.
Knowledge 10 triplets contain
xin two-depths graph traversal:x -> y(from node 1)
x -> a(from node 2)
x -> m(from node 4)
x <- b-> c(from node 95)
x -> d(from node 96)
n -> x(from node 98)
x <- z <- i(from node 1 and node 3)
x <- z <- b(from node 1 and node 95)
And clearly, the refined information related to topic x that comes from both other nodes and across the nodes is included in the context to build the prompt of in-context learning.
Progress of Knowledge Graph in Llama Index
The Knowledge Graph abstraction was initially introduced to Llama Index by William F.H. where the triplets in the knowledge graph were associated with the docs with keywords and stored in memory, then Logan Markewich enhanced it by adding embedding per triplets, too.
Recently, in the last couple of weeks, I had been working with the community on bringing the “GraphStore” storage context to Llama Index and thus introducing external storage of Knowledge Graph, the first implementation is NebulaGraph the Open-Source Distributed Graph Database that I had been working on since 2021.
During the implementation of this, the option to traverse multiple hops of the graph, and the option to collect more key entities on top-k nodes(to search in the knowledge graph to enable more global context) was introduced, and we are still refining the changes.
With GraphStore introduced, it also makes it possible to perform in-context learning from an existing knowledge graph, combined with other indices, this is also quite promising due to the knowledge graph being considered with high Information density than other structured data.
About NebulaGraph Database
As a high-performance native distributed graph database, NebulaGraph Database excels in handling mega data sets with hundreds of billions of nodes and trillions of edges, while maintaining millisecond query latency. Relying on its shared-nothing, distributed architecture and computation-and-storage separation, it is highly available, highly secure, and easy to scale out, largely meeting the security requirements of enterprises. Besides, it can be deployed on the public cloud and on-premises as needed.
Talk to a Graph Database Expert
Get a customized solution for your organization and see how NebulaGraph can help you:
