Tech-talk
Thoughts after attending the SIGMOD'22 conference
This year's SIGMOD'22 was held in Philadelphia, and I was honored to attend as a speaker on behalf of the company. During this conference, I communicated a lot with students, professors, and companies. On the one hand, I publicized our products; on the other hand, I got many valuable suggestions and opinions. Next, I'll share some of these suggestions, as well as my overall thinking.
Graph learning and storage technology have attracted much attention
There are two hotspots that most participants pay attention to at this conference, which reflects the new trend in the industry.
First, the importance of machine learning is further increasing, and graph learning is becoming a new hotspot. In recent years, more and more conferences that focus on specific systems set sections about machine learning to study the use of machine learning in optimizing systems or algorithms. Among the sub-fields of machine learning, a new force, i.e., graph learning, which is machine learning on graphs, suddenly rises. Just like other sub-fields of machine learning, graph learning also aims at solving problems in the real world. Through the method of embedding, graph learning extracts feature vectors from a graph, and then uses machine learning methods to solve complex problems in the graph, including classification, subgraph matching, an d link classification.
Judging by the tendency of conferences and guidance from the National Science Foundation (NSF), this trend is likely to continue. We have also received a lot of inquiries from students and professors about whether NebulaGraph supports graph learning. From a graph database provider's perspective, graph learning is one of the NebulaGraph application scenarios. We should provide not only the graph database core, but also libraries, interfaces, and even optimizations for upper-layer applications to ensure the smooth and efficient operation of upper-layer applications. On the other hand, if NebulaGraph can help academia make some breakthroughs in areas like graph learning, it'll be great for our company, and the industry as a whole.

In addition to machine learning, I think another hotspot is memory, including in-memory databases, persistent memory, etc. Non-volatile memory, or persistent memory, has become more and more mature through the joint efforts of academia and industry for more than ten years. Research on how to use persistent memory is also very hot, and there are numerous articles on it at top events of almost all systems.
In the database field specifically, research topics include how to design an in-memory database, how to mix durable memory with SSD, DRAM, and other types of storage, and how to solve the problem of memory segregation. NebulaGraph, as a graph database provider, should be embracing the changes that new hardware brings, and exploring persistent memory-based storage systems as well.
The advantages and development direction of the graph
**In addition to the new trends, my biggest takeaway and thought from the conference was the comparison between graph databases (GDBMS) and relational databases (RDMBS). **There were quite a few people at the conference who were wondering why the graph database was not implemented based on a relational database, because relational databases have been optimized over the years, and they are really armed to the teeth. For example, Professor Peter Boncz (one of the founders of LDBC) gave a keynote address at the EDBT/ICDT conference earlier this year on The (Sorry) State of Graph Database Systems [1]. He stated that compared with RDBMS, GDBMS still had a lot to improve in terms of computation and storage, especially regarding AP queries like subgraph matching. He proposed a performance benchmark for subgraph matching scenarios. In his experimental environment, none of the graph database software came close to the performance of relational databases Hyper and Umbra in the subgraph matching scenario (see the following figure).
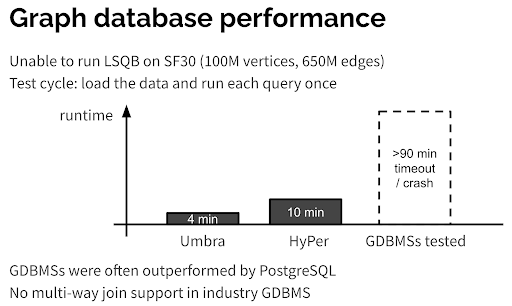
Certainly, the setup of this experiment is worthy of discussion. Still, Peter, as a founder of LDBC, did not mean to disparage graph databases but to encourage graph database providers to improve their products by using subgraph matching, a query scenario in which graph databases are not well optimized.
From the broader picture, NebulaGraph, as a graph database provider,** must know the differences between graph databases and relational databases and grasp the advantages of graph databases. For example, GQL is easier to use and more efficient when executing graph queries than SQL**. Emil Eifrem, CEO of Neo4J, has a perfect example [3]: For a very common query in an AP system, if using SQL, it needs a very long statement consisting of 23 SELECTs, 21 WHEREs, 11 JOINs, and 9 UNIONs. But if you use a graph query language, you only need a MATCH and a WHERE. For SQL, the query task may be impossible to complete or easy to go wrong, but for a graph query language, the task is easy to complete, saving countless manpower and resources.
In terms of performance, in addition to the natural advantages of graph databases over relational databases in association relation queries, i**t is also necessary to gain an advantage over relational databases in a variety of other graph-related queries (not limited to subgraph matching mentioned above). **This is actually the core enlightenment of Peter's proposal of subgraph query as a benchmark for us.
Thoughts about the underlying storage structure

At last, we also gained a number of suggestions for the underlying storage. NebulaGraph currently applies RocksDB, which is based on LSM-Tree, as the underlying storage engine. However, it has been controversial whether LSM-Tree is suitable for the workload of the graph database, especially, whether it is the best choice with the lowest cost on the cloud. Possible alternatives are:
Bε-tree File System, or betrFS. https://www.betrfs.org/
LiveGraph. https://marcoserafini.github.io/papers/LiveGraph.pdf
B+ Tree. We will follow up the research on this aspect.
All in all, the SIGMOD'22 trip was fruitful. Look forward to SIGMOD next year. See you in Seattle!
[1] https://conferences.inf.ed.ac.uk/edbticdt2022/?contents=invited_talks.html
[3] https://people.eecs.berkeley.edu/~istoica/classes/cs294/15/notes/21-neo4j.pdf