Technical Deep Dives
Jan 30, 2023
Difference Between Distribution and Partitioning in Graph Databases
Dr. Min WU
What is a distributed system?
Generally, a distributed system is a set of computer programs that work together across multiple independent servers to achieve a common goal. Those servers refer to those commodity servers instead of mainframes. The hardware for cross-server collaboration here is mostly based on Ethernet devices or higher-end RMDA devices.
Why do we need a distributed system?
The main reason to build a distributed system is to replace the cost of expensive hardware devices with software technology and inexpensive hardware devices. Especially in most private server rooms, not public cloud or supercomputing conditions, procurement costs are an important basis for business decisions.
In addition to reducing costs, another benefit of distributed technology is its scalability. By adding several servers to the original number of servers, and then combining the scheduling and distribution ability of the distributed system, the new servers can be used to provide additional services.
Compared with purchasing more servers in equal numbers or purchasing higher configuration servers, the distributed technology allows you to purchase servers on demand, which reduces the risk of over-provisioning and improves the utilization rate of the hardware resources.
Basic problems with distributed systems
In distributed technologies, since data storage and computation need to be implemented across multiple independent servers, a series of underlying technologies must be involved. In this article, we discuss only two problems: One is the data copy or replica problem, and another is how to distribute the storage and computation of large data to independent servers.
The problem of data replicas
The hardware reliability and maintenance of commodity servers are much lower than that of mainframes. Because loose network cables, damaged hard drives, and power failures occur almost every hour in large machine rooms. It is a basic problem for a distributed software system to solve or avoid these hardware problems. One common solution is to replicate data on multiple servers. Once some data replicas are lost, the system can still provide services by using the remaining data replicas. What's more, when the access load of the system is too large, the system can also provide more services by adding more replicas. In addition, some technologies are needed to ensure that the data replicas are consistent with each other, that is, the data of each replica on different servers is the same. For graph databases, the data replica problem also exists. The way to solve this problem is similar to the way to solve the data replica problem in relational databases or big data systems.
The problem of data partitioning
The hardware, memory, and CPU of a single server are limited. If the data is too large, it is impossible to store all the data on a single server. Therefore, the TB-level or even PB-level data must be distributed to multiple servers, and we call this process data partitioning. When a request is to access multiple data partitions, the distributed system needs to distribute the request to each correct data partition and then combine the results.
The problem of data partitioning in graph databases - graph partitioning
In graph databases, the distribution process is imaginatively called graph partitioning. A big graph is partitioned into multiple small graphs, and the storage and computation of each small graph are stored on different servers. Compared with the partitioning problem in relational databases and big data systems, the graph partitioning problem deserves more special attention.
Let's take a look at a static graph structure, such as the CiteSeer dataset, which is a citation network of scientific papers, consisting of 3312 papers and their citations between them. It is a small-scale dataset, so it can be stored on a single server.
The Twitter 2010 dataset, is a social network of Twitter users, consisting of 12.71 million vertices and 0.23 billion edges. It is relatively easy to store this dataset on a single mainstream server produced in 2022. However, it may be necessary to purchase very expensive high-end servers produced 10 years ago to do so.
However, the WDC (Web Data Commons) dataset, consists of 1.7 billion vertices and 64 billion edges. It is difficult or impossible to store such a large-scale dataset on a current mainstream server.
On the other hand, since the data of human beings is growing faster than Moore's Law and the number of connections or relationships between data is exponentially higher than the speed of data production, the data partitioning problem seems to be an inevitable problem for the graph database system. But it sounds no different from the way data is partitioned or hashed in the mainstream distributed technologies. After all, data is partitioned into multiple big data systems.
Wait, is it that easy to partition a graph?
No, it is not. In the field of graph databases, the graph partitioning problem is a trade-off among technologies, products, and engineering.
Three problems faced by graph partitioning
The first problem - what should be partitioned? In big data or relational database systems, row-based partitioning or column-based partitioning is performed based on records or fields, or partitioning is performed based on data IDs, and these are intuitive in terms of semantics and technology. However, the strong connectivity of the graph data structure makes it difficult to partition the graph data. One vertex may be connected to many other vertices through multiple edges, and the other vertices may also be connected to many other vertices through their neighboring edges. It is just like the web pages that are almost linked to each other. So for a graph database, what should be partitioned that can make the semantics intuitive and natural? (In RDBMS, this is equivalent to how to partition the data when there are a large number of foreign keys in the table.) Of course, there also exist some natural semantic partitioning methods. For example, under the COVID-19 epidemic, the transmission chain of various strains in China and other countries are two different network structures.
Then, a second problem is introduced.
The second problem - how to ensure that the data of each partition is roughly balanced after the data is partitioned. The naturally formed graphs conform to the power low that a minority of 20% vertices are connected to other 80% vertices, and these minority vertices are called super nodes or dense nodes. This means that the minority vertices are associated with most of the other vertices. Therefore it can be expected that the load and hotspots of the partition containing the super nodes are much higher than that of the other partitions containing the other vertices.

The above image shows the visual effect of the association network formed by hyperlinks to websites on the Internet, where the super websites (nodes) are visible.
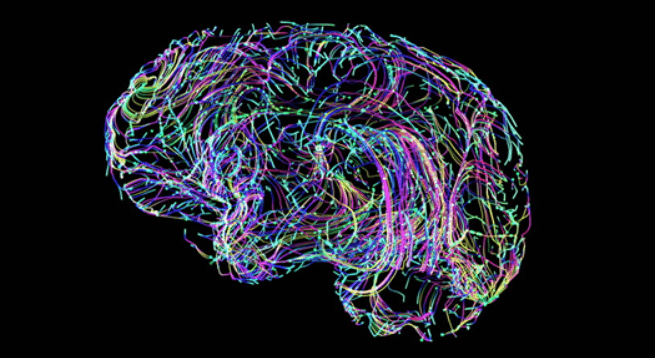
The third problem - how to evaluate and perform repartitioning when the original partitioning methods are gradually outdated as the graph network grows and the graph distribution and connection patterns change? The following image shows the visual effect of the connections among 86 billion neurons in the human brain. With learning, exercise, sleep, and aging, neuronal connections are constantly changing at the weekly level. The original partitioning method may not be able to keep up with the changes at all.
Of course, many other details need to be considered. In this article, we try to avoid using too many technical terms.
Unfortunately, there is no silver bullet for the graph partitioning problems from a technical point of view and each product has to make its trade-offs.
Here are some examples of the trade-offs made by different products.
Partitioning methods in different graph database products
1. Distributed but unpartitioned
Neo4j 3.5 adopts the unpartitioned distributed architecture.
The reason to use a distributed system is to ensure the consistency and the read availability of the written data in multiple replicas.
That means the full amount of graph data is stored on each server, and the size of data cannot be larger than the capacity of a single server's memory and hard disk. We can ensure the failure of a single server in the process of data writing by adding multiple write replicas. We can improve the read performance by adding multiple read replicas (The write performance is not improved).
This solution can avoid the above-mentioned three problems of graph data partitioning and in theory, there is nothing wrong with calling such a solution a distributed graph database.
To add to that, since the data is complete on each server, ACID transactions are relatively easy to implement.
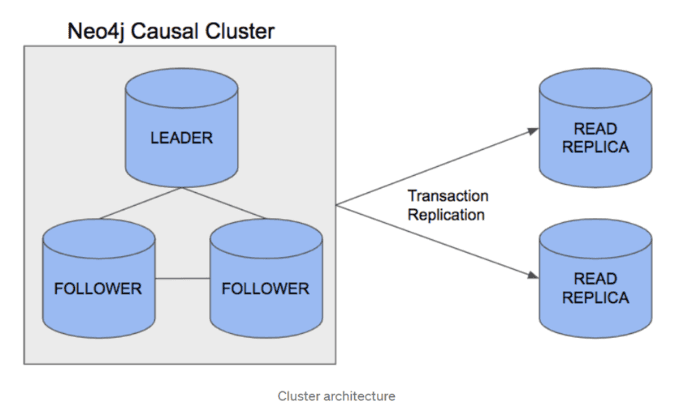
For details about the Neo4j 3.5 causal cluster architecture, see https://medium.com/neo4j/querying-neo4j-clusters-7d6fde75b5b4.
2. Distributed and partitioned by users
The distributed and partitioned by users architecture is typically represented by Neo4j 4.x Fabric. Depending on the user's business case, users can specify that subgraphs can be placed on a (group of) server(s). For example, in one cluster, the subgraph of the product E is placed on the server E and the subgraph of the product N is placed on server N. (Of course, for the availability of the service itself, these servers can also be placed in the Causal Cluster mentioned in the above-mentioned image.) In this process, for both the write and read operations, the user needs to specify a server or a group of servers to operate.
This solution leaves the above-mentioned three problems to the user for decision at the product level. Such a solution is also called a distributed graph database.
What's more, this solution can guarantee the ACID transactions in server E. However, there are a certain amount of edges that connect the vertices in server E and the vertices in other servers, so the ACID transactions of these edges cannot be guaranteed technically.
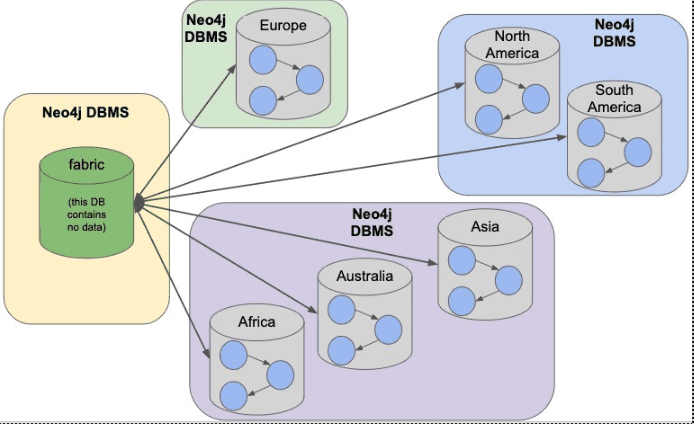
For details about the Neo4j 4.x Fabric architecture, see https://neo4j.com/developer/neo4j-fabric-sharding/.
3. Non-equivalent distributed, partitioned, and coarse-grained replicated
This solution allows multiple replicas and graph data partitioning, and these two processes require a small number of users to be involved.
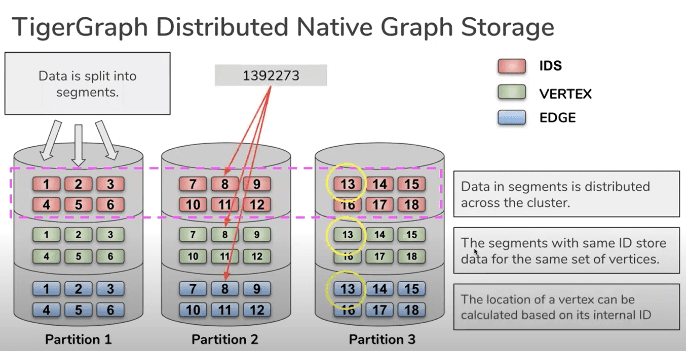
For details about TigerGraph's partitioning solution, see https://www.youtube.com/watch?v=pxtVJSpERgk.
In TigerGraph's solution, vertices and edges are scattered in multiple partitions after being encoded.
The first two problems among the above-mentioned problems can be partially solved by encoding vertices and edges. Users can make decisions on whether to read or compute the data in a distributed system or a single server.
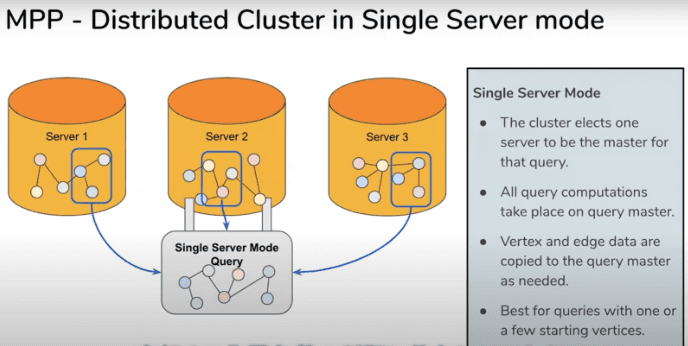
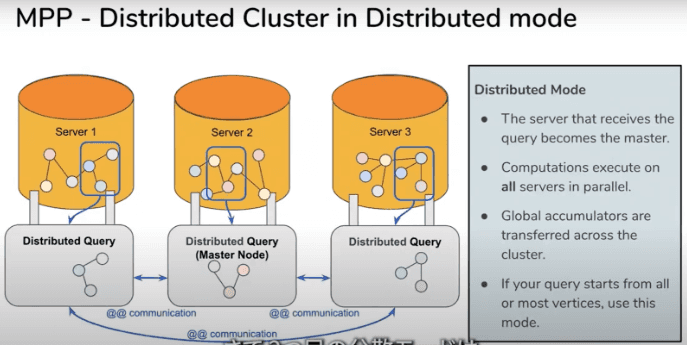
The above image shows TigerGraph's single read mode and parallel computing mode.
However, such a set of partitions must be replicated in full and identical copies (so the granularity of the scale-out is the entire graph instead of a partition), which requires a larger amount of storage space.
4. Full-equivalent distributed, partitioned, and fine-grained replicated
There are also solutions whose architectural design purpose ranks graph scalability or resiliency relatively at the highest priority of the overall system design. The assumption is that data is being generated faster than Moore's Law, and the interactions and relationships between data are exponentially higher than the rate of data generation. Therefore it is necessary to be able to handle the such explosive growth of data and provide services quickly.
In this solution, the obvious characteristic is the separation design of the storage layer and the computing layer, each having the ability for fine-grained scalability.
Data is partitioned in the storage layer with a hash or consistent hash solution. Hashing is performed based on the IDs of vertices or primary keys. This solution just solves the first problem.
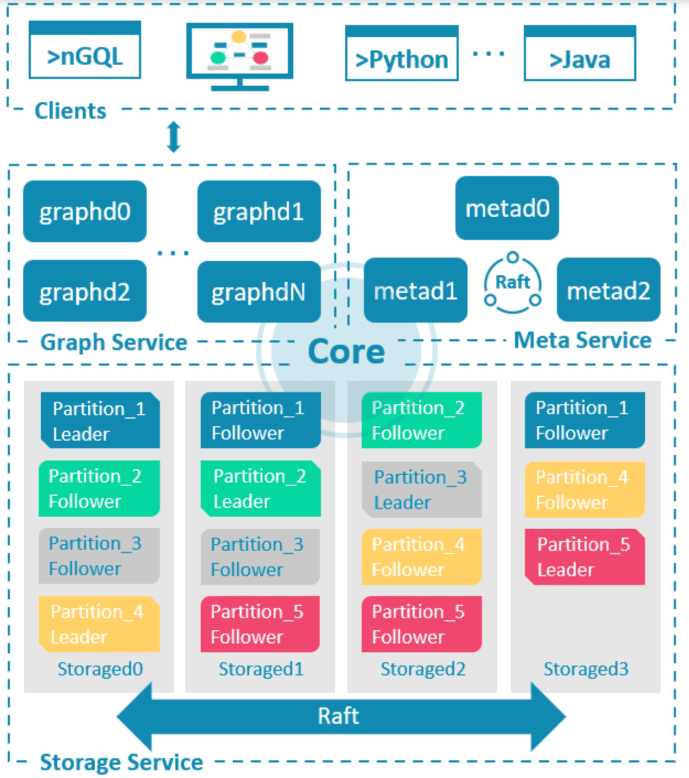
For details about the architecture of NebulaGraph, see the paper Wu, Min, et al. "Nebula Graph: An open-source distributed graph database." arXiv preprint arXiv:2206.07278 (2022).
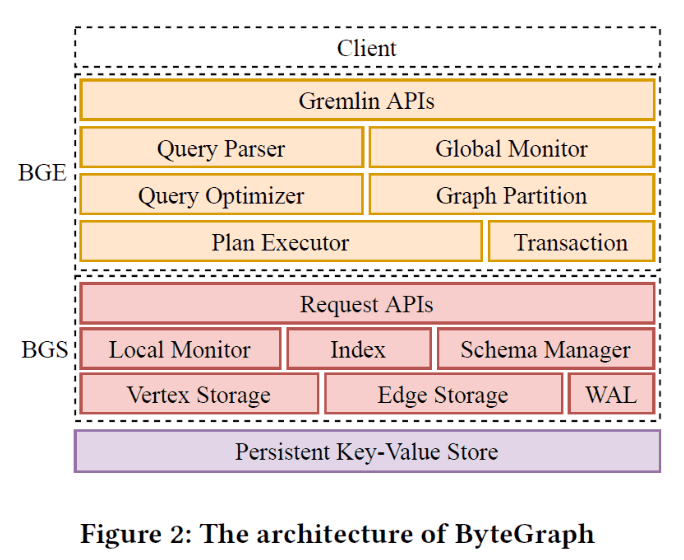
For details about the architecture of ByteGraph, see Li C, Chen H, Zhang S, et al. ByteGraph: A High-Performance Distributed Graph Database in ByteDance[J].
To deal with the super node and load balancing problem (the second problem), another layer of the B-tree data structure is introduced. It splits super nodes into multiple processing units, balances data among threads, and scales out the computing layer.
For the third problem, the solution is to use a fine-grained partitioning method so that the scale-out of some partitions can be performed.
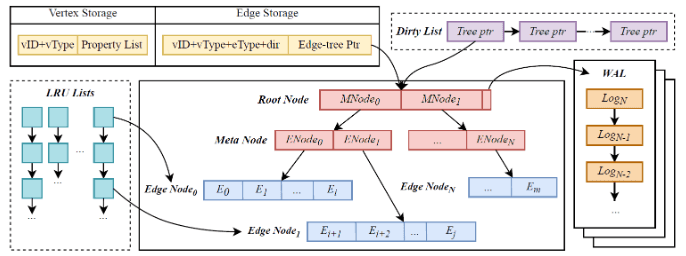
For sure, this solution is also called a distributed graph database.
The above-mentioned four solutions make different trade-offs at the product and technical levels, with a focus on suitable business scenarios. These solutions can all be called distributed graph databases.
Extended reading
The problem of graph partitioning
There has been a lot of research on how to partition graphs on a single machine. Here is the recommended tool METIS http://glaros.dtc.umn.edu/gkhome/metis/metis/overview.
Graph partitioning is a very difficult problem in a distributed system. The following articles are recommended for further reading.
https://dgraph.io/blog/post/db-sharding/
https://hal.inria.fr/hal-01401338/document
https://docs.janusgraph.org/advanced-topics/partitioning/
About Pseudo-Distributed Mode
Generally, this mode uses only a single node and simulates the distributed mode. It is recommended to use this mode for studying and debugging.
An overview of the graph databases
Sahu, S., Mhedhbi, A., Salihoglu, S., Lin, J., ¨Ozsu, M.T.: The ubiquity of large graphs and surprising challenges of graph processing: an extended survey. VLDB J. 29(2-3), 595–618 (2020)
Sakr, S., Bonifati, A., Voigt, H., Iosup, A., Ammar, K., Angles, R., Yoneki: The future is big graphs: a community view on graph processing systems. Communications of the ACM 64(9), 62–71 (2021)
Disclaimer
The above-mentioned solutions are the author's understanding and should not be used as a reference for making investment decisions. If there are any errors, please feel free to point them out.
To reduce the difficulty of reading, the author has simplified the description of the solutions, which does not mean that the original solutions are so simple.
